




La necesidad de jerarquizar y estructurar correctamente la
información, no sólo para almacenarla, sino también para acceder a ella, se ha
convertido en una labor que ha cobrado especial relevancia en los últimos años,
en los que se han producido importantes avances en este campo.
Inicialmente se usaron las Definiciones del Tipo de
Documento (DTDs) en el lenguaje SGML
para describir el vocabulario necesario para identificar todos
los elementos de que iba a constar el documento y para expresar la estructura. La aparición y el desarrollo del lenguaje XML, hizo
que este lenguaje incorporara también las
DTDs,
no en vano, hay que recordar que el lenguaje XML no es sino un subconjunto del lenguaje
SGML.
Pero las
DTDs no
satisficieron todas las necesidades inherentes a XML y pronto se vio necesario
utilizar otros métodos más rigurosos y sofisticados para tratar la estructura
y la semántica dentro de un documento XML. Así surgieron los Esquemas XML (XML Schema),
como una forma de ampliación y mejora de las primitivas DTDs. Las DTDs y los
Schemas son usados por los analizadores sintácticos o
parsers para comprobar si un documento XML es válido.
Así pues, vemos que para
proceder a la estructuración
o especificación formal dentro de un documento XML existen distintas soluciones,
entre las que cabe destacar principalmente dos: las DTDs y los XML Schemas.
Pero veamos con
más profundidad las diferencias entre la utilización de DTDs y Esquemas.
La Declaración de Tipo de Documento (DTD-Document Type Data):
Al definir el lenguaje XML ya nos
referimos a la Definición del Tipo de Documento (Document
Type Definition DTD)
que, en resumen, cumple las siguientes funciones:
- Una DTD especifica la clase de documento
- Describe un formato de datos
- Usa un formato común de datos
entre aplicaciones
- Verifica los datos al
intercambiarlos
- Verifica un mismo conjunto de
datos
- Una DTD describe
- Elementos: cuáles son las etiquetas permitidas
y cuál es el contenido de cada etiqueta
- Estructura:
en qué orden van las etiquetas en el documento
- Anidamiento: qué etiquetas van dentro de cuáles
Los elementos de una DTD son los siguientes:
- Elementos con
“contenido ELEMENT”:
- Un elemento tiene contenido ELEMENT, si
solo puede contener a otros elementos, opcionalmente separados por espacios
en blanco.
- Elementos con “contenido TEXT”
- Un elemento tiene contenido TEXT, si solo puede
contener texto
- (PCDATA = printable character data)
- Elementos con “contenido MIXED”
- Un elemento tiene contenido MIXED, si puede contener texto u otros
elementos
- Elementos con “contenido EMPTY”
- Un elemento tiene contenido EMPTY, si no puede contener otros
elementos
Y los atributos son los siguientes:
- CDATA: texto
- NMTOKEN: “abc...z0123..9-_:.” (tipo de
lista)
- NMTOKENS: NMTOKEN + espacios
- ID: empezar con letra
- IDREF: ser un ID
Así pues, la DTD
especifica la clase de documento XML. Una DTD indica sólo qué
elementos, atributos, etc; tiene un documento y cómo se anidan, pero no dice
nada acerca de tipos de dato. El único tipo de dato que conoce es
CDATA (texto
plano), por tanto, las DTDs se quedan algo cortas y cuando se necesita algo más
potente y rígido, se usa Schema
Recordemos que una DTD se
puede guardar en un archivo de texto, como por ejemplo, en el archivo "list.dtd".
Una DTD muy simple es la
siguiente:
<!ELEMENT List (Item)+>
<!ELEMENT Item (#PCDATA)>
<!ATTLIST Item
id CDATA IMPLIED
color CDATA IMPLIED>
<!ELEMENT Separator EMPTY>
Veamos
ahora el documento .xml que hace referencia a esa DTD:
<?xml version="1.0" encoding="iso-8859-1"?>
<!DOCTYPE list SYSTEM "list.dtd">
<List>
<Item>París</Item>
<Item>Madrid</Item>
<Separator />
<Item
color="rojo">Londres</Item>
</List>
XML Schema:
Al igual que las DTDs, los Schemas
describen el contenido y la estructura de la información, pero de una forma más
precisa.
Los esquemas indican tipos
de dato, número mínimo y máximo de ocurrencias y otras características más
específicas.
Según la Especificación
del W3C XML Schema (http://www.w3.org/XML/Schema), los esquemas expresan vocabularios compartidos que permiten a las máquinas
extraer las reglas hechas por las personas. Los esquemas proveen un significado para definir la
estructura, contenido y semántica de los documentos XML.
Un esquema XML (XML
schema) es algo similar
a un DTD, es decir, define qué elementos puede contener un documento XML, cómo
están organizados, y qué atributos y de qué tipo pueden tener sus elementos,
pero la utilización de schemas ofrece nuevas posibilidades en el tratamiento
de los documentos.
La ventaja de utilizar los schemas con respecto a los DTDs
son:
- Usan sintaxis de XML, al contrario que los
DTDs.
- Permiten especificar los tipos de datos.
- Son extensibles (esto es, permite crear
nuevos elementos).
Por ejemplo, un schema nos permite
definir el tipo del contenido de un elemento o de un atributo, y especificar si
debe ser un número entero, una cadena de texto, una fecha, etc. Las DTDs no
nos permiten hacer estas cosas.
Veamos un ejemplo de un documento XML, y su schema
correspondiente:
<documento xmlns="x-schema:personaSchema.xml">
<persona id="fulanito">
<nombre>Fulano Menganez</nombre>
</persona>
</documento>
Como podemos ver en el documento XML
anterior, se hace referencia a un espacio de nombres
(namespace) llamado "x-schema:personaSchema.xml". Es decir, le estamos
diciendo al analizador sintáctico XML (parser) que valide el documento
contra el schema "personaSchema.xml".
El schema sería algo parecido a esto:
<Schema xmlns="urn:schemas-microsoft-com:xml-data"
xmlns:dt="urn:schemas-microsoft-com:datatypes">
<AttributeType name='id' dt:type='string' required='yes'/>
<ElementType name='nombre' content='textOnly'/>
<ElementType name='persona' content='mixed'>
<attrubyte type='id'/>
<element type='nombre'/>
</ElementType>
<ElementType name='documento' content='eltOnly'>
<element type='persona'/>
</ElementType>
</Schema>
El primer elemento del schema
define dos espacios de nombre. El primero
"xml-data"
le dice al analizador (parser) que esto es un schema y no otro
documento XML cualquiera. El segundo "datatypes" nos permite definir el tipo de
elementos y atributos utilizando el prefijo "dt".
-
ElementType:
Define el tipo y contenido de un elemento, incluyendo los sub-elementos que
pueda contener.
-
AttributeType:
Asigna un tipo y condiciones a un atributo.
-
attribute:
Declara que un atributo previamente definido por AttributeType
puede aparecer como atributo de un elemento determinado.
-
element:
Declara que un elemento previamente definido por ElementType
puede aparecer como contenido de otro elemento.
Así pues, es necesario empezar el
schema definiendo los elementos más profundamente anidados dentro de la
estructura jerárquica de elementos del documento XML. Es decir, tenemos que
trabajar "desde dentro hacia fuera", o lo que es lo mismo, las declaraciones de
tipo ElementType
y AttributeType
deben preceder a las declaraciones de contenido element y
attribute
correspondientes.
Un esquema también puede verse como una colección
(vocabulario) de definiciones de tipos y declaraciones de elementos cuyos
nombres pertenecen a un determinado espacio de nombres
llamado espacio de nombres de destino. Los espacios de nombres de destino hacen
posible la distinción entre definiciones y declaraciones de diferentes
vocabularios. Por ejemplo, los espacios de nombres de destino facilitarían la
declaración del elemento
element
en el vocabulario del Esquema XML, y la declaración de
element
en un hipotético vocabulario de lenguaje químico. El primero es parte de espacio
de nombres de destino
http://www.w3.org/2001/XMLSchema, y el segundo es
parte de otro espacio de nombres de destino.
Además, a medida que los esquemas se hacen más grandes, es
posible y deseable dividir su contenido entre varios documentos esquema con el
fin de facilitar su mantenimiento, control de acceso, y legibilidad.
Las Recomendaciones establecidas por el
W3C en relación a
los esquemas XML son las siguientes:
-
XML Schema Part 0: Primer.
Es un documento no normativo que pretende ofrecer una fácil descripción de las
funcionalidades de XML Schema y que está orientado a comprender de forma
rápida cómo crear esquemas utilizando el lenguaje XML Schema.
http://www.w3.org/TR/xmlschema-0/
-
XML Schema Part 1: Structures.
Especifica la definición del lenguaje XML Schema y ofrece las
herramientas para describir la estructura y constreñir el contenido de los
documentos de XML 1.0, incluyendo las que tratan los
espacios de nombre (XML Namespace). El lenguaje de
esquemas que se representa en XML usa espacios de nombre,
reconstruye sustancialmente y extiende las capacidades de las DTDs de los documentos del lenguaje XML 1.0.
http://www.w3.org/TR/xmlschema-1/
-
XML Schema Part 2: Datatypes.
Establece las herramientas para definir los tipos de datos que se usan en los
esquemas XML y en otras especificaciones XML. El lenguaje de tipo de datos que
se representa en XML 1.0, ofrece un conjunto de capacidades que se encontraban
en las DTDs en XML 1.0
para especificar tipos de datos sobre elementos y atributos.
http://www.w3.org/TR/xmlschema-2/
DTD versus Schema
Las limitaciones de la DTD
son las siguientes:
-
Posee un
lenguaje propio de escritura lo que ocasiona problemas a la hora del
aprendizaje, pues no sólo hay que aprender XML, sino también conocer el
lenguaje de las DTDs.
-
Para
el procesado del documento, las herramientas y
analizadores (parsers) empleados para tratar los documentos XML deben ser capaces de procesar
también las DTDs .
-
No permite el uso de
namespaces y estos son muy útiles ya que permiten definir elementos con igual nombre dentro del
mismo contexto, siempre y cuando se anteponga un prefijo al nombre del
elemento.
-
Tiene una tipología para los
datos del documento extremadamente limitada, pues no permite definir el que un
elemento pueda ser de un tipo número, fecha, etc. sino que sólo presenta
variaciones limitadas sobre cadenas.
-
El mecanismo
de extensión es complejo y frágil ya que está basado en sustituciones sobre
cadenas y no hace explicitas las relaciones, es decir, que dos elemento que tienen definido el mismo modelo de
contenido no presentan ninguna relación.
Estos problemas son superados gracias a la especificación de
XML Schema, ya que los esquemas permiten un lenguaje mucho más expresivo y
un intercambio de información mucho más robusto. Pero, aparte de solventar los problemas antes expuestos,
XML Schema, permite una serie de ventajas adicionales:
-
XML
Schema presenta una estructura de tipos
mucho más rica. En la segunda parte de la especificación de XML Schema
(XML Schema Part 2: Datatypes) se definen los tipos base que se pueden
emplear dentro de esquema de XML, como ejemplo podemos destacar: byte, integer,
bolean, string, date, sequence, etc. Este
sistema de tipos es muy adecuado para importar y exportar sistemas de
bases de datos y, sobre todo, distingue los
requerimientos relacionados con la representación léxica de los datos y el
conjunto de información dominante y subyacente.
-
Permite tipos definidos por
el usuario, llamados Arquetipos. Dando un nombre a estos arquetipos, se
pueden usar en distintas partes dentro del Schema.
-
Es posible agrupar
atributos, haciendo más comprensible el uso de un grupo de aspectos de varios
elementos distintos, pero con un denominador común, que deben ir juntos en cada
uno de estos elementos.
-
Es
posible trabajar con espacios de nombre, según la Especificación
XML Schema Part
0: Primer, permitiendo validar documentos con varios
namespaces.
-
Con XML Schema es
posible
extender Arquetipos de un modo específico, es decir permite lo que en
términos de orientación a objetos se llama herencia. Considérese un
esquema que extiende otro previamente hecho, se permite refinar la
especificación de algún tipo de elemento para, por ejemplo, indicar que puede
contener algún nuevo elemento del tipo que sea; pero dejando el resto del
esquema antiguo completamente intacto.
En la siguiente imagen
podemos comprobar la gran riqueza de los tipos de datos y la estructuración
jerárquica que ofrece XML Schema:
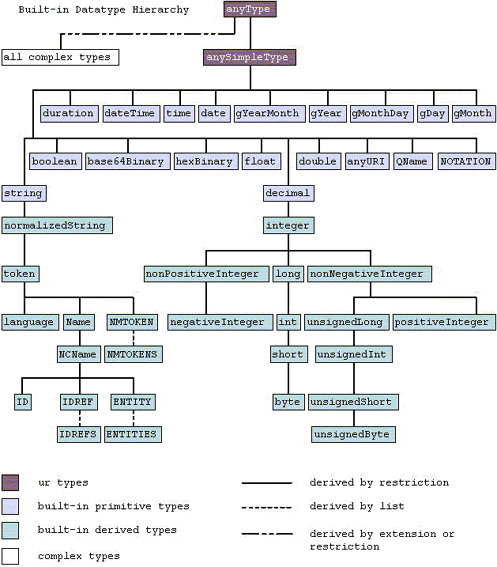
Fuente: W3C. XML Schema Part 2: Datatypes Second Edition.
http://www.w3.org/TR/xmlschema-2/
De las DTDs a XML
Schema
Como hemos afirmado anteriormente, en los inicios de XML se emplearon las DTDs
como modo de especificación de modelos, pero en la actualidad su uso ha quedado
algo restringido y lo normal es utilizar el de XML
Schema.
En la siguiente tabla se
puede ver la
correlación entre elementos de XML Schema y de DTDs, aunque existen herramientas de traducción (DTD2HTML
en Perl
http://www.w3.org/2000/04/schema_hack/), XMLSpy
http://www.xmlspy.com) entre estos 2
lenguajes.
|
DTD
|
XML Schema |
Comentarios
|
|
ELEMENT |
<element> |
Crea un vínculo entre un nombre y unos atributos, modelos de contenido y
anotaciones |
| #PCDATA |
Soportado como parte de un tipo simple |
|
| ANY |
<any> |
Posee distintos comodines para un mayor conjunto de
posibilidades. Existe también <anyAttribute> con comodines similares. |
| EMPTY |
Soportado |
Se elimina la existencia de elementos descendientes del actual,
diferenciando de la presencia de un string vacío en un elemento. |
| Modelo de Contenido |
<complexType> |
|
| , (Conector de secuencia) |
<sequence> |
|
| | (Conector de alternativas) |
<disjunction> |
|
| ? (Opcional) |
Soportado |
Se han de emplear los atributos predefinidos de maxOccurs y minOccurs |
|
+(Requerido y Repetible) |
Soportado |
Se han de emplear los atributos predefinidos de maxOccurs y minOccurs |
| *(Opcional y Repetible) |
Soportado |
Se han de emplear los atributos predefinidos de maxOccurs y minOccurs |
| ATTLIST |
<attributeGroup> |
Se pueden agrupar declaraciones de <attributes> |
| Tipo de atributo CDATA, ID, IDREF, NOTATION... |
Tipos <simpleType>predefinidos |
|
| ENTITY |
NO Soportado |
Las entidades son declaradas en declaraciones de marcas en el XML |
|
ENTITY%Parameter |
NO
Soportada |
Las
entidades paramétricas ofrecen un mecanismo de bajo nivel que permite
distintas cosas, algunas de estas se han intentado cubrir en XML
Schema:
-
..
La separación entre <element> y <complexType>
-
..
Grupos de atributos
-
..
Grupos de modelos con nombre
-
..
Mecanismos de extensión y restricción de tipos
-
..
Los mecanismos de <import> e <include> para componer
esquemas
-
..
El mecanismo de redefinición de elementos
|
En resumen, para
modelar y validar la información
existen muchas maneras de hacerlo, entre las que destacan el uso de DTDs y
de XML Schema,
entre otras. La utilización de XML Schema se ve favorecida por la facilidad de tratamiento que se deriva de la
escritura en XML, en lugar de emplear otros parsers para su
reconocimiento, y también porque el estándar está muy extendido.
Otra gran ventaja es que gracias a XML Schema se pueden
expresar un gran número de tipos de datos y jerarquizarlos. También es posible expresar la carga semántica y esto es muy importante para el
tratamiento de la información. Si gracias a XML se han
podido realizar intercambios de información entre aplicaciones de muy distinta
índole, mediante XML
Schema se ha podido validar y estructurar su contenido. Los esquemas XML
avanzan un paso más en la consecución de la Web
Semántica.
Existen numerosos esquemas, muchos de ellos
utilizan el lenguaje RDF escrito en XML, es decir
RDF Schema.
Por ejemplo,
FOAF: el proyecto "Friend Of A Friend" (amigo de un amigo)
http://www.foaf-project.org/
es una aplicación de
XML y
RDF. Básicamente es un
archivo XML (en realidad,
RDF
escrito en XML) con el cual se describen
personas,
documentos, etc.
FOAF se basa en la idea de que cuando
hablamos de describir a una persona, no estamos hablando de sus atributos físicos, sino de datos más profundos como: a quién conoce, de quién es amigo y
de quién no, cuáles son sus proyectos actuales y cuáles los pasados, etc. Todo,
o casi todo, puede ser definido en un archivo FOAF.
Leandro Mariano López
explica de forma sencilla en FOAF: el proyecto 'friend to
friend' en qué consiste este vocabulario. "Existen en el mundo cientos de miles de
personas que comparten los mismos atributos, como el nombre, color de ojos, pelo,
altura, intereses, etc. Sabiendo esto, ¿cómo podemos llegar a distinguir de
quién estamos hablando? ¿Cómo identificar de un modo unívoco a alguien? Como
FOAF es un proyecto basado en Internet, los desarrolladores buscaron algún
atributo propio de los usuarios de Internet, y lo encontraron: el
e-mail". FOAF se expresa como un
RDF Schema para expresar el hecho de que un
foaf:mbox únicamente se refiere a un individuo.
FOAF:mbox es una propiedad inambigua
(UnambiguousProperty).
De esta forma, el correo electrónico
personal se convierte en una propiedad no ambigua acerca de una persona, ya que
puede convertirse en identificador único de
alguien.
Otro ejemplo de este tipo de esquemas es el elaborado por
Leandro Mariano López: Esquema Habla, Lee y Escribe http://purl.org/net/inkel/rdf/schemas/lang/index.html
que permite identificar qué idiomas puede hablar, leer o escribir una persona. El esquema se
encuentra localizado en
http://purl.org/net/inkel/rdf/schemas/lang/1.1 Un ejemplo de implementación
puede encontrarse en el archivo FOAF, en
http://purl.org/net/inkel/inkel.foaf.rdf
Leandro Mariano López expresa de estas forma la
propiedades definidas por este esquema:
Declaración espacio de nombres:
xmlns:lang="http://purl.org/net/inkel/rdf/schemas/lang/1.1#"
-
lang:speaks
- Indica que la Persona puede hablar en este lenguaje
-
lang:reads
- Indica que la Persona puede leer este lenguaje
-
lang:writes
- Indica que la Persona puede escribir en este lenguaje
-
lang:masters
- Indica que la Persona puede hablar, leer y escribir en
este lenguaje
Se puede crear un perfil FOAF desde
http://my.opera.com/community/sparql/. Además, se ofrece una
interfaz que permite hacer búsquedas en toda la información pública.
Similar a FOAF es XFN (XHTML Friends
Network)
http://gmpg.org/xfn/
una manera muy simple para representar las relaciones humanas usando
hiperenlaces. Se utiliza mucho en la
blogosfera. XFN hace
posible que los autores web indiquen sus relaciones simplemente con añadir el
atributo rel a sus etiquetas <a
href>
Ejemplo:
<a href="http://jane-blog.example.org/"
rel="sweetheart date met">Jane</a>
<a href="http://dave-blog.example.org/" rel="friend met">Dave</a>
<a href="http://darryl-blog.example.org/" rel="friend met">Darryl</a>
<a href="http://www.metafilter.com/">MetaFilter</a>
<a href="http://james-blog.example.com/" rel="met">James Expert</a>
También existe otra iniciativa llamada
DOAP (Description of a Project)
http://usefulinc.com/doap/.
Se trata de un vocabulario XML/RDF para describir proyectos de software
libre que usa la URL del proyecto como clave
primaria. Con DOAP se pueden hacer descripciones semánticas del proyecto,
describir los recursos asociados, los participantes y los recursos web. Para
ello se utilizan algunas características ya empleadas en RSS,
FOAF o Dublin Core. DOAP puede
interoperar con todos estos esquemas de metadatos y
puede ser extendido para propósitos específicos.
Por su parte,
Charles McCathieNevile en El código EARL por ejemplos:
http://www.w3.org/2001/sw/Europe/talks/200311-earl/all.es
nos ofrece un vocabulario para describir si algo cumple con determinados requisitos. Por
ejemplo, si una página es accesible o cumple con determinadas pautas de
accesibilidad (WCAG).




