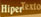

 


Dado que XML es un lenguaje
utilizado
ampliamente en el desarrollo de la World Wide Web, existen ya herramientas y
estándares de programación para leer documentos XML. Las herramientas o
programas que leen
el lenguaje XML y comprueban si el documento es válido sintácticamente, se denominan analizadores
o "parsers". Un parser XML
es un módulo,
biblioteca o programa que se ocupa de transformar un archivo de
texto en una
representación interna. En el caso de XML, como el formato siempre es el mismo,
no necesitamos crear un parser cada vez que hacemos un programa, sino que
existen un gran número de parsers o analizadores sintácticos disponibles que pueden averiguar si un
documento XML cumple con una determinada gramática. Entre esos analizadores o
parsers cabe destacar DOM
y SAX.
DOM y SAX, son pues dos herramientas que sirven
para analizar el lenguaje XML y definir la estructura de un documento, aunque
existen otras muchas. Podemos hacer una distinción entre las herramientas que
son
validantes y las que son No validantes. Las primeras verifican que el documento, además de estar bien formado de
acuerdo a las reglas de XML, responda a una estructura definida en una
Definición del Tipo de Documento (DTD).
Los parsers DOM y SAX son independientes
del lenguaje de programación y existen versiones particulares para
Java, VisualBasic,
C, etc.
DOM
El Modelo de Objetos del Documento
 o
Document
Object Model (DOM) es un modelo de objetos estandarizado para
documentos HTML y XML.
DOM es
un conjunto de interfaces para describir una
estructura abstracta para un documento XML.
Los programas que acceden a la estructura de un documento a través de la
interfaz de DOM pueden insertarse arbitrariamente, borrarse y reordenar los
nodos de un documento XML, esto es, con DOM se puede modificar el contenido, la
estructura y el estilo o presentación de los documentos. Todas estas funciones
se realizan mediante llamadas a funciones y procedimientos que permiten acceder,
cambiar, borrar o añadir nodos de información (datos o
metadatos) de los documentos XML. o
Document
Object Model (DOM) es un modelo de objetos estandarizado para
documentos HTML y XML.
DOM es
un conjunto de interfaces para describir una
estructura abstracta para un documento XML.
Los programas que acceden a la estructura de un documento a través de la
interfaz de DOM pueden insertarse arbitrariamente, borrarse y reordenar los
nodos de un documento XML, esto es, con DOM se puede modificar el contenido, la
estructura y el estilo o presentación de los documentos. Todas estas funciones
se realizan mediante llamadas a funciones y procedimientos que permiten acceder,
cambiar, borrar o añadir nodos de información (datos o
metadatos) de los documentos XML.
DOM es una
una interfaz de programación de aplicaciones
(API) para documentos
HTML
y XML. Define la estructura lógica de los documentos y
el modo en que se accede y manipula un documento. El término documento en DOM se
entiende de una forma amplia, pues XML se utiliza cada vez más como un medio
para representar muchas clases diferentes de información que puede ser
almacenada en sistemas diversos, y mucha de esta información se vería, en
términos tradicionales, más como datos que como documentos. Sin embargo, XML
presenta estos datos como documentos, y se puede usar el DOM para manipular
estos datos.
Con el Modelo de Objetos del Documento los programadores
pueden construir documentos, navegar por su estructura, y añadir, modificar o
eliminar elementos y contenido. Se puede acceder a cualquier cosa que se
encuentre en un documento HTML o XML, y se puede modificar, eliminar o añadir
usando el Modelo de Objetos del Documento, salvo algunas excepciones.
Siendo una especificación del W3C, uno de los objetivos
importantes del Modelo de Objetos del Documento es proporcionar una interfaz
estándar de programación que pueda utilizarse en una amplia variedad de entornos
y aplicaciones. El DOM se ha diseñado para utilizarse en cualquier lenguaje
de
programación como Java o ECMAScript (un lenguaje de scripts industrial basado en JavaScript
y JScript.
Cuando nos referimos a interfaz al hablar de DOM (o de SAX),
no nos estamos refiriendo a interfaz gráfica, sino a
interfaz de aplicaciones. Una interfaz es un dispositivo que permite comunicar
dos sistemas que no hablan el mismo lenguaje. Una Interfaz de Programación de Aplicaciones
 o
API (Application Programming interface)
es un conjunto de funciones o métodos usados para
acceder
a cierta funcionalidad. La interfaz
se encarga de mantener el diálogo con los datos para poder tener acceso a
ellos y manipularlos. o
API (Application Programming interface)
es un conjunto de funciones o métodos usados para
acceder
a cierta funcionalidad. La interfaz
se encarga de mantener el diálogo con los datos para poder tener acceso a
ellos y manipularlos.
La utilización de APIs es muy común cuando tenemos un
conjunto de datos que queremos tratar o manipular y se aplica, sobre todo, para
acceder a bases de datos y realizar tareas que están a caballo entre las aplicaciones
y las
bases de datos. Estas tareas se realizan bien a través del
servidor de base
de datos, o bien a través del cliente. Esto quiere decir, que
puede darse el caso de que el cliente conste de las tres primeras interfaces o
niveles, o que se encuentren las dos últimas en el servidor (ver
imagen adjunta). La interfaz correspondiente a la
base de datos, es donde se
encontrará el servidor y toda la información depositada en él.
El DOM es, pues, un API o interfaz de programación para
documentos. DOM guarda una gran similitud con la estructura del documento al que
modeliza y muestra los documentos con una estructura lógica que es muy parecida
a un árbol.



Sin embargo, el DOM no especifica que los documentos deban
ser desarrollados como un árbol o un bosque, ni tampoco especifica cómo
deben implementarse las relaciones entre objetos. El DOM es un modelo lógico que
puede desarrollarse de la manera que sea más conveniente, por eso se debe hablar
de un modelo de estructura en general, y no de estructura en forma de
árbol, en particular.
Una propiedad importante de los modelos de estructura del DOM
es su isomorfismo estructural: si dos
desarrollos cualesquiera del
Modelo de Objetos del Documento se usan para crear una representación del mismo
documento, ambos crearán el mismo modelo de estructura, con exactamente los
mismos objetos y relaciones.
El nombre de DOM o "Modelo de Objetos del Documento"
se adoptó porque se trata de un "modelo de objetos" en el sentido tradicional del diseño orientado a
objetos: los documentos se modelizan usando objetos, y el modelo comprende no
solamente la estructura de un documento, sino también su comportamiento y el de los objetos de los cuales se compone.
Esto significa que los
nodos del diagrama obtenido mediante DOM no representan una estructura de datos, sino que
representan objetos, los cuales pueden tener funciones e identidad. Como modelo
de objetos, el DOM identifica:
-
las interfaces y objetos usados para representar y
manipular un documento
-
la semántica de estas interfaces y objetos,
incluyendo comportamiento y atributos
-
las relaciones y colaboraciones entre estas
interfaces y objetos
Tradicionalmente, la estructura de los documentos
SGML se ha representado mediante un modelo de datos
abstractos, no con un modelo de objetos. En un modelo de datos abstractos, el
modelo se centra en los datos. En los lenguajes de programación orientados a
objetos, los datos se encapsulan en objetos que ocultan los datos,
protegiéndolos de su manipulación directa desde el exterior. Las funciones
asociadas con estos objetos determinan cómo pueden manipularse los objetos, y
son parte del modelo de objetos.
El Modelo de Objetos del Documento no es un conjunto de
estructuras de datos, sino un modelo de objetos que especifica interfaces.
Aunque la especificación del W3C contiene diagramas que muestran relaciones padre/hijo,
éstas son relaciones lógicas definidas por las interfaces de programación, no
representaciones de ninguna estructura interna de datos particular.
El Modelo de Objetos del Documento no define "la semántica
interna real" de los lenguajes XML o de HTML. El DOM es un modelo de
programación diseñado para respetar las semánticas establecidas por el W3C en
otras especificaciones. El DOM no tiene ninguna consecuencia en el modo en que
se escriben los documentos XML y HTML; cualquier documento que pueda escribirse
con estos lenguajes puede ser representado en el DOM.
Así pues, DOM es un conjunto de interfaces y objetos diseñado
para manipular documentos HTML y XML que se puede desarrollar usando otros
sistemas y lenguajes específicos.
Las especificaciones del W3C que regulan el Modelo de Objetos
del Documento son las siguientes:
En esta especificación se define el Nivel 1 del Modelo de Objetos del Documento, una
interfaz independiente de la plataforma y del lenguaje que permite a programas y
scripts acceder y actualizar dinámicamente los contenidos, la estructura y el
estilo de los documentos. El Modelo de Objetos del Documento proporciona un
conjunto estándar de objetos para representar documentos HTML y XML, un modelo
estándar de cómo pueden combinarse estos objetos y una interfaz estándar para
acceder a ellos y manipularlos. Las compañías pueden dar soporte al DOM como
interfaz para sus estructuras de datos y APIs propietarias, y los autores de
contenido pueden escribir para las interfaces estándar del DOM en lugar de para
las APIs específicas de cada producto, lo cual incrementa la interoperabilidad
en la Web.
El objetivo de la especificación DOM es definir una interfaz programable para
HTML y XML. La especificación del Nivel 1 del DOM se divide en dos partes:
Núcleo y HTML. El núcleo proporciona un
conjunto de interfaces fundamentales de bajo de nivel que pueden representar
cualquier documento estructurado, al mismo tiempo que define interfaces
extendidas para representar documentos XML. La sección de HTML proporciona interfaces adicionales de alto nivel que se utilizan
con las interfaces fundamentales definidas en la sección sobre el Núcleo del
Nivel 1 para proporcionar una visión más conveniente de los documentos HTML.
- Document Object Model (DOM) Level 2
agrupa
las siguientes especificaciones:
Estas Recomendaciones definen el Document Object Model
Nivel 2 que se construye sobre el Document Object Model Nivel, pero añadiendo un conjunto de interfaces
especializadas para crear y manipular la estructura y el contenido del
documento.
El Document
Object Model Core Level 3 se construye sobre el Document Object Model Level 2,
completa el mapeado entre DOM y el conjunto de información XML [XML
Information Set:
http://www.w3.org/TR/xml-infoset/]
, incluyendo soporte para XML Base [http://www.w3.org/TR/xmlbase/], añade la posibilidad de adjuntar información del usuario a los nodos
DOM, ofreciendo mecanismos para resolver los
prefijos de los espacios de nombre o para manipular
atributos "ID" para tipificar la información, etc.
SAX
El Simple API for XML
(SAX)
es una interfaz simple para aplicaciones XML. Fácil e intuitiva, muchos
programadores de
Java la utilizan, ya que se usa especialmente en
situaciones en los que los archivos XML ya están en una forma que es
estructuralmente similar a la que deseamos obtener.
Por lo general, se usa SAX cuando la información almacenada en los documentos XML, es decir, los datos, han
sido generados por máquina o son legible por máquina. En este caso, SAX es la
forma más directa de API para que los programas tengan acceso a esa información.
Los datos generados y legibles por máquina incluyen algunos elementos como los
siguientes:
Así, los datos generados por la máquina son información que normalmente
tenemos creada en estructuras de datos y clases para
Java. Un ejemplo simple
de este tipo, puede ser una libreta de direcciones. La
libreta en un archivo XML contiene puramente datos que pueden ser codificados
como texto usando XML, no se trata, pues de algo similar a un documento creado
con un procesador de textos, sino a datos en sí mismos.
Cuanto los datos son de este tipo, lo
corriente es crear una
estructura de datos y clases, es decir, un modelo de objetos (object models) para
poder ordenar, manipular y almacenar estos datos. SAX permite crear rápidamente una
herramienta u operador de
clase que puede crear instancias de los modelos de objetos basados en el
almacenamiento de datos de los documentos. Por ejemplo, un operador de
documentos SAX que
lee un documento XML que contiene una Libreta de direcciones y crea una
clase Libreta de direcciones que puede usarse para acceder a esta
información. El documento XML Libreta de direcciones contiene elementos
Persona, los cuales contienen, por ejemplo, los elementos nombre y
correo electrónico. El modelo de objeto Libreta de direcciones contendría
las siguientes clases:
- Clases Libreta de Direcciones, que es un contenedor para
objetos Persona.
- Clase Persona, que es un contenedor para la cadena de objetos
nombre y correo electrónico.
Así el operador del documento Libreta de direcciones SAX,
es el responsable de colocar los elementos persona
dentro de los objetos Persona, y almacena todo en un objeto: Libreta de
Direcciones. Este documento coloca los elementos nombre y correo electrónico
dentro de una cadena de objetos.

Comparación entre SAX y DOM
Un analizador (parser)
SAX es una
herramienta más versátil, más veloz y menos potente que un analizador (parser) DOM. SAX requiere una mayor programación, pero puede ser muy
útil si lo que interesa es rescatar un fragmento de un
documento o buscar sólo un elemento en particular.
En contraste, un DOM
es menos versátil, más lento, pero una vez usado no hay que desarrollar nada
más. Con DOM se obtiene el árbol ya construido y listo para poder funcionar.
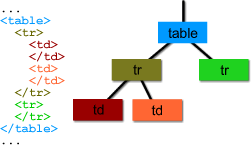
Un parser DOM tiene una interfaz de estilo como la
que sigue:
nodoRaiz = domParse(
documento )
Y lo que produce es un árbol
de nodos. En este ejemplo produciría algo así -considerando una notación
tipo LISP- en la que el primer elemento de las listas es la raíz::
(p "Bienvenidos" (b
"compañeros"))
Un parser SAX tiene una interfaz del estilo
de este tipo:
saxParse( documento,
f_inicio_elemento, f_fin_elemento, f_texto )
En donde los principales
argumentos son punteros a
 funciones. Estas funciones serán ejecutadas por el parser cuando
éste se encuentre con un elemento inicial, con uno final, o con
texto. funciones. Estas funciones serán ejecutadas por el parser cuando
éste se encuentre con un elemento inicial, con uno final, o con
texto.
Por ejemplo, en el
documento <p>Bienvenidos <b>compañeros</b></p>, si ejecuto
saxParse(
documento, fstart, fend, ftext ), se produce la siguiente secuencia de
invocaciones:
fstart(http://www.w3.org/TR/REC-xml-names/"p")
ftext("Bienvenidos")
fstart("b")
ftext("compañeros")
fend("b")
fend("p")
Obviamente, un DOMParser
puede implementarse encima de un SAXParser.
nodo_actual = null
define fstart(elemento) :=
( nodo_actual == null ) ? nodo_actual = elemento : nodo_actual.agregaHijo(
elemento )
define fend(elemento) :=
nodo_actual = nodo_actual.obtienePadre()
define ftext(texto) :=
nodo_actual.guardaContenido( texto )
saxParse( document, fstart, fend, ftext )
return nodo_actual
Hay que agregar una serie
de salvedades que permiten ir verificando en línea que se cierren todos los
elementos que se abran, etc.
Respecto a los atributos: es una extensión de
este tipo de parsing.

Estructura jerárquica de un Objeto de
Documento (DO-Document Object)
El operador del documento SAX tiene elementos para mapear los objetos. Si la información está estructurada de
alguna manera que pueda ser fácil crear este mapa, se debería usar API de SAX.
Por el contrario, si los datos están mucho mejor representados en forma de árbol,
entonces se debería usar DOM.
Cómo operan DOM y SAX
Los parsers DOM y SAX trabajan de diferente manera.
SAX necesita menos código y menos memoria, aunque tiene menos
capacidad que DOM. El funcionamiento es el siguiente: primero se comienza a leer
el documento, luego se detectan los eventos de parsing (como por ejemplo
comienzos o finales de un elemento), la aplicación procesa esa parte leída y,
por último, se reutiliza la memoria y se vuelve a leer hasta un nuevo evento.
Así pues, el parser SAX
procesa el documento XML analizando la corriente de entrada XML, pasando los
eventos SAX a un método para operar con una programación definida.
Un parser DOM,
por el contrario, opera con la corriente completa de entrada XML, es decir, lee
todo el documento completo y devuelve un Document Object. Document, esto es, construye un árbol en memoria que refleja toda la estructura del
documento. La aplicación recorre el árbol realizando su procesamiento ya que el documento
devuelto por el parser DOM tiene un API que permite manipular el árbol (virtual)
de Node objects. É ste representa la estructura de la entrada XML.
La principal diferencia entre DOM y SAX es
que mientras el primero tiene acceso al documento completo, esto es, que
todos los elementos y atributos están disponibles a la vez, en SAX sólo está
disponible el elemento actual.
Las siguientes figuras
ilustran las diferencias entre las APIs de SAX y DOM.
 
Fuente: Mark Johnson. Programming XML in Java. DOMination:
Take control
of structured documents with the Document Object Model.
http://www.javaworld.com/javaworld/jw-07-2000/jw-0707-xmldom.html
Cuándo usar DOM y cuándo usar SAX:
Si los documentos XML contienen documentos de datos almacenados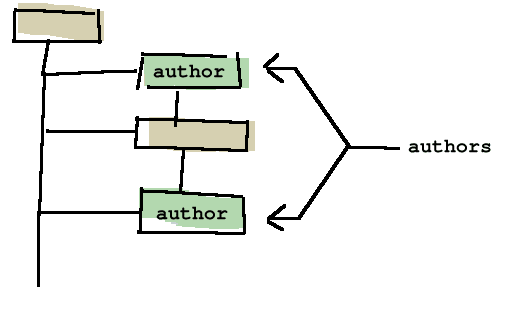 en un formato XML, entonces
lo natural es usar DOM. Si por ejemplo, se está creando alguna clase de sistema
de gestión de la información y se tiene un gran número de documentos de datos de
diferentes tipo (como archivos de Word o Excel) y esos documentos pueden
organizarse e indexarse desde toda clase de documentos fuente, DOM permitirá acceder a los programas que
almacenan la información en esos documentos. en un formato XML, entonces
lo natural es usar DOM. Si por ejemplo, se está creando alguna clase de sistema
de gestión de la información y se tiene un gran número de documentos de datos de
diferentes tipo (como archivos de Word o Excel) y esos documentos pueden
organizarse e indexarse desde toda clase de documentos fuente, DOM permitirá acceder a los programas que
almacenan la información en esos documentos.
En DOM, se pueden generar consultas (queries) usando XPAth. Con este
lenguaje, se pueden expresar cosas tales como: dame todos los nodos que se
llaman "x" y que tienen un nodo hijo llamado "y" con el
conjunto de atributos "z" para un valor cierto.
Sin embargo, si se está tratando principalmente con estructuras de datos, DOM no es la mejor elección. En
ese caso es mejor usar SAX.
| DOM (Document Object Model) |
SAX |
| Estructura en árbol |
Modelo de eventos |
| Bueno para editar el documento |
Bueno si no se necesita transformar en
memoria |
| Bueno si necesitas realizar múltiples
procesados |
Menor gasto de memoria |
| Evita tener que volver a analizar el
documento |
Bueno si sólo se necesitan partes de
documentos |
| Evita tener que construir tu propio árbol |
Permite
recorrer secuencialmente un documento XML y responder a una serie de eventos |

Niveles DOM. Anatomía de un documento. Fuente:
Mark Johnson. Programming XML in Java.
DOMination: Take control of structured
documents with the Document Object Model.
http://www.javaworld.com/javaworld/jw-07-2000/jw-0707-xmldom.html
Además, tanto DOM como SAX cuentan con sus propias
APIS para analizar las hojas de
estilo: CSS-DOM y SAC (Simple API for CSS), respectivamente.
(W3C:
CSS-DOM
http://www.w3.org/TR/DOM-Level-2-Style/ y
(W3C. SAC: The Simple API for CSS.
http://www.w3.org/Style/CSS/SAC/)
Bibliografía:
 CASTILLO, Carlos. Parsing
XML. Sax y Dom.
http://www.tejedoresdelweb.com/307/article-2146.html
CASTILLO, Carlos. Parsing
XML. Sax y Dom.
http://www.tejedoresdelweb.com/307/article-2146.html
IDRIS,
Nazmul.
Should I Use SAX or DOM?
http://developerlife.com/saxvsdom/default.htm
W3C. Document Object Model (DOM) Level 1 Specification.
http://www.w3.org/TR/REC-DOM-Level-1/
(traducción al castellano: POZO, Juan R. Especificación del Modelo de Objetos
de Documento. Nivel 1.
http://html.conclase.net/w3c/dom1-es/cover.html)
W3C. Document Object Model (DOM) Level 2 Core Specification.
http://www.w3.org/TR/DOM-Level-2-Core/
W3C. Document Object Model (DOM) Level
3 Core Specification.
http://www.w3.org/TR/DOM-Level-3-Core/
W3C.
Document Object Model (DOM) Technical Reports.
http://www.w3.org/DOM/DOMTR
W3C.
Document Object Model FAQ.
http://www.w3.org/DOM/faq.html
W3C.Extensible Markup Language XML. W3C Recommendation.
http://www.w3.org/TR/REC-xml/
W3C. What does your user agent claim to support?
http://www.w3.org/2003/02/06-dom-support.html (traducción al
castellano: GUTIÉRREZ FERRERÍAS, Fernando. ¿Qué afirma soportar su Agente de
Usuario?
http://ferguweb.tx.com.ru/w3/06-dom-support.html)
W3C. XML
Information Set:
http://www.w3.org/TR/xml-infoset/
| 



