María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen.
|
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. |
|
| ||||||||||||||||||||
|
El tamaño de Internet en terabytes |
|
|
Media |
2002 Terabytes |
|
Web navegable |
167 |
|
Web profunda |
91.850 |
|
E-mail (originales) |
440.606 |
|
Mensajería instantánea |
274 |
|
TOTAL |
532.897 |
Fuente: How much information 2003 (traducción propia)
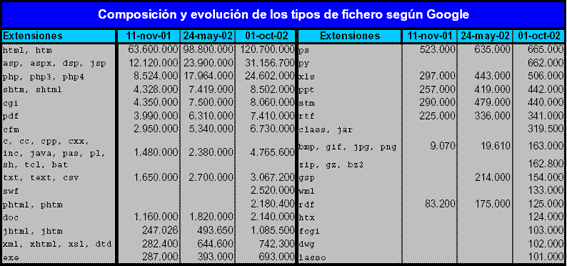
En capítulos anteriores hemos visto un gráfico con la composición de la Web navegable y los tipos de archivo en la Web, el resto de ese inmenso océano es, precisamente, lo que constituye la la llamada Web invisible, una enorme parte de la Web que está compuesta por enormes bases de datos a las que los usuarios no pueden llegar con los métodos de búsqueda tradicionales.
¿Qué información es la que permanece invisible? Toda aquella información almacenada en bases de datos, material de archivo y herramientas interactivas tales como diccionarios o calculadoras, páginas dinámicas construidas con tecnologías Flash, ASP, PHP, etc. Estos recursos son embebidos dentro de miles de sitios web individuales y no son "visibles" para los motores de búsqueda tradicionales. Para acceder a todo ese incalculable acervo de información sólo podemos interrogar a las bases de datos directa e individualmente a través de sus propios formularios de búsqueda, puesto que las páginas indizables por los motores de búsqueda no dan cuenta de los recursos en ellas disponibles. Lo que está claro es que nadie tiene acceso completo a todo Internet ya que no sólo existen áreas concretas de la red que son inaccesibles a la mayor parte de los internautas, sino también determinados contenidos que permanecen invisibles.
Ricardo Fornas Carrasco en La cara oculta de Internet establece 3 tipos distintos de Internet:
Internet global: Definiremos ésta como aquella Red de información libre y gratuita que es accesible teóricamente mediante la interconexión de ordenadores. La forma de acceso se realiza mediante programas navegadores, Chats, mensajería o intercambio de protocolos (FTP, P2P).
Internet invisible: Responde a todos aquellos contenidos de información que están disponibles en Internet pero que únicamente son accesibles a través de páginas generadas dinámicamente tras realizar una consulta en una base de datos. Esta particular naturaleza les hace inaccesibles a los procesos habituales de recuperación de la información que realizan buscadores, directorios y agentes de búsqueda. Pero podemos acceder a las mismas mediante nuestras habituales herramientas de navegación, correo, etcétera. La única condición es saber exactamente la dirección de acceso (URL o FTP)
Internet oscuro: Se define como los servidores o host que son totalmente inaccesibles desde nuestro ordenador. Según un estudio de la compañía Arbors Networks esta situación sucede en el 5% de los contenidos globales de la Red. La causa principal (78 % de los casos) se debe a zonas restringidas con fines de seguridad nacional y militar. No olvidemos que Internet es un invento militar. El porcentaje restante, (22%) obedece a otros motivos: configuración incorrecta de routers, servicios de cortafuegos y protección, servidores inactivos y finalmente "secuestro" de servidores para utilización ilegal.
Al igual que la Internet invisible, la denominada Web invisible contiene un gran número de fuentes de información que no pueden buscarse porque su contenido no ha sido indizado ni puede serlo por los principales buscadores. Aun cuando recuperemos un sitio que contenga una base de datos, es improbable que el buscador conduzca a la base de datos misma, puesto que requiere que se navegue por el sitio web para encontrarla. Así pues, la Web invisible está constituida por toda esa información accesible vía web, pero a la que no es posible llegar mediante una consulta a los buscadores tradicionales.
Por su parte, Isidro Aguillo en Internet invisible distingue entre Infranet y Web invisible, que describe de la siguiente forma:

Fuente: Isidro Aguillo: Internet invisible.
http://internetlab.cindoc.csic.es/cursos/Internet_Invisible2003.pdf
Toda esta rica información ha sido inexplorada hasta ahora. Sin embargo, existen en la red, determinados buscadores que sí indizan -y bucean- en parte de esa Web invisible. Entre ellos podemos destacar:
Internetinvisible.com (en español): recopila, describe y ofrece los enlaces a las bases de datos españolas gratuitas existentes en Internet. Ofrece, además de un formulario de búsqueda directa simple y avanzada, un directorio organizado en grupos temáticos, los cuales se subdividen a su vez en materias más específicas. Tras la consulta, se obtiene una ficha con la descripción del contenido de la base de datos relacionada, el enlace a la pantalla de búsqueda y la entidad o persona responsable de su creación. Existen enlaces a más de 2.400 bases de datos de acceso gratuito. Esta web pretende ser el directorio de referencia del contexto español (tanto lo producido en el estado español, en cualquiera de sus lenguas oficiales, como lo procedente de otros lugares geográficos de temática o habla hispana). También incluye recursos ajenos cuando constituyen un punto de referencia en su campo de aplicación. http://www.internetinvisible.com/
InvisibleWeb.com (en inglés): es un directorio que contiene unas 10.000 bases de datos y archivos que contienen información que tradicionalmente no puede ser accedida por los buscadores tradicionales. http://www.invisibleweb.com
Invisible Web Directory: La Web profunda por temas. http://www.invisibleweb.net/
Complete Planet: The Deep Web Directory contiene unas 70.000 bases de datos de la red profunda y otros recursos especializados. http://aip.completeplanet.com
Direct Search: es una compilación de enlaces e interfaces de búsqueda de recursos que contienen datos que no son fácilmente accesibles o "buscables" por los buscadores generalistas. http://www.freepint.com/gary/direct.htm
Turbo10: buscador que da acceso a más de 800 motores de búsqueda. http://turbo10.com
The Big Hub: acceso a más de 1.500 bases de datos con un buscador propio. http://www.thebighub.com

Fuente: Ricardo Baeza Yates. http://www.dcc.uchile.cl/~rbaeza/inf/webfaces.gif
Como afirma Ricardo Baeza Yates en Excavando la Web:
"la web tiene actualmente al menos unas cuatro mil millones de páginas estáticas y un número cientos de veces mayor de dinámicas (aquellas que sólo se crean producto de un clic o de una consulta en un sitio web). Además, tenemos que agregar toda la web invisible, en intranets o páginas con acceso restringido. La web oculta es seguramente miles de veces más grande que la pública".En la figura anterior se muestra claramente que la Web indizable es sumamente pequeña en el conjunto de la Web y que la región indizable, esto es, de la que efectivamente pueden extraer información los buscadores, es muy pequeña y se corresponde en gran parte con la zona pública estática. La figura también muestra que, en la actualidad, las páginas con información semántica son muy pocas, por lo que la Web Semántica, queda todavía lejos.
![]() AGUILLO, Isidro. "Internet invisible o Infranet: definición, clasificación y evaluación".
VII Jornadas Españolas de
Documentación. Bilbao, Universidad del País Vasco, 2000.
AGUILLO, Isidro. "Internet invisible o Infranet: definición, clasificación y evaluación".
VII Jornadas Españolas de
Documentación. Bilbao, Universidad del País Vasco, 2000.
![]() AGUILLO, Isidro. Internet
invisible: Los contenidos son la clave. CINDOC-CSIC, 2003.
http://internetlab.cindoc.csic.es/cursos/Internet_Invisible2003.pdf
[Volver]
AGUILLO, Isidro. Internet
invisible: Los contenidos son la clave. CINDOC-CSIC, 2003.
http://internetlab.cindoc.csic.es/cursos/Internet_Invisible2003.pdf
[Volver]
![]()
![]() BERGMAN, Michael K. "The Deep Web: Surfacing Hidden Value" (BrightPlanet
White Paper). http://www.brightplanet.com/technology/deepweb.asp
BERGMAN, Michael K. "The Deep Web: Surfacing Hidden Value" (BrightPlanet
White Paper). http://www.brightplanet.com/technology/deepweb.asp
![]() CyberAtlas, citing the CIA World Factbook
http://cyberatlas.internet.com/big_picture/geographics/article/0,1323,5911_151151,00.html
CyberAtlas, citing the CIA World Factbook
http://cyberatlas.internet.com/big_picture/geographics/article/0,1323,5911_151151,00.html
![]() FORNAS CARRASCO,
Ricardo. "La cara oculta de Internet". Hipertext.net, núm. 1, 2003
http://www.hipertext.net/ [Volver]
FORNAS CARRASCO,
Ricardo. "La cara oculta de Internet". Hipertext.net, núm. 1, 2003
http://www.hipertext.net/ [Volver]
![]() InvisibleWeb.com (en inglés)
http://www.invisibleweb.com/
InvisibleWeb.com (en inglés)
http://www.invisibleweb.com/
![]() Internetinvisible.com (en castellano)
http://www.internetinvisible.com/
Internetinvisible.com (en castellano)
http://www.internetinvisible.com/
![]() LARDY, Jean-Pierre.
http://www.addnb.fr/article.php3?id_article=35
LARDY, Jean-Pierre.
http://www.addnb.fr/article.php3?id_article=35
![]() LYMAN, Peter and VARIAN, Hal R. How Much Information? 2003
http://www.sims.berkeley.edu/research/projects/how-much-info-2003/printable_report.pdf
y
http://www.sims.berkeley.edu/research/projects/how-much-info-2003/internet.htm
[Volver]
LYMAN, Peter and VARIAN, Hal R. How Much Information? 2003
http://www.sims.berkeley.edu/research/projects/how-much-info-2003/printable_report.pdf
y
http://www.sims.berkeley.edu/research/projects/how-much-info-2003/internet.htm
[Volver]
![]() SALAZAR, Idoia. "El inmenso océano del
Internet profundo". Ciberp@is, 25 de octubre de 2005.
SALAZAR, Idoia. "El inmenso océano del
Internet profundo". Ciberp@is, 25 de octubre de 2005.
![]() SALAZAR, idoia. Las profundidades de
Internet: Accede a información que los buscadores no encuentran y descubre el
futuro inteligente de la red. Gijón, Ediciones Trea, 2006.
SALAZAR, idoia. Las profundidades de
Internet: Accede a información que los buscadores no encuentran y descubre el
futuro inteligente de la red. Gijón, Ediciones Trea, 2006.
![]() SHERMAN,
Chris. The invisible Web
http://www.freepint.com/issues/080600.htm#feature
SHERMAN,
Chris. The invisible Web
http://www.freepint.com/issues/080600.htm#feature
URL:
http://www.hipertexto.info
Fecha de Actualización:
08/12/2013
Fundación Ricardo Lamarca, Ajedrez y
cultura
http://www.fundacionlamarca.es
Mapa de navegación
/ Tabla de contenido /
Mapa conceptual /
Tabla de documentos /
Buscador /
Bibliografía utilizada / Glosario de Términos /
Índice Temático /
Índice de Autores
![]()
![]()
![]()
Autora: María Jesús Lamarca Lapuente (currículo personal)
34.389 enlaces (10.436 externos y 23.953 internos)
![]()
Creative Commons
Reconocimiento-NoComercial-NoDerivados-Licencia España 2.5.
OTRAS PÁGINAS DE LA AUTORA
![]() Blog
El Cultural a la Puerta::
http://puertadetoledo.blogspot.com/
Blog
El Cultural a la Puerta::
http://puertadetoledo.blogspot.com/ 
Ageteca. Base de Datos de Gestión
Cultural:
http://www.agetec.org/ageteca


![]()
digital y
mundo analógico:
http://www.flickr.com/photos/artesadigital/

![]()
|
|