
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen.
|
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. |
|
| ||||||||||||
| Granularidad consistente | Capaz de identificar un conjunto de documentos a partir de una palabra clave |
| Granularidad media | Capaz de identificar un documento específico a partir de una palabra clave |
| Granularidad fina | Capaz de identificar la localización de una frase o una palabra en un documento a partir de una palabra clave |
Google es de los pocos motores de búsqueda que ha hecho público el funcionamiento de su sistema y el algoritmo (PageRank) con el que lleva a cabo su ranking de resultados. Este motor de búsqueda no sólo tiene en cuenta los enlaces incluidos dentro de una página web, sino también los enlaces que apuntan hacia esa página desde el exterior. Así pues, Google hace uso de la conectividad, una de las principales características de la hipertextualidad de la Web para calcular el grado de calidad e importancia de cada página. Este motor de búsqueda se compone de 2 módulos que llevan a cabo la indización: un indexador y un clasificador. El primero lee las páginas y los enlaces, los analiza y selecciona; y el segundo resume el documento en un conjunto de palabras y le otorga un orden de posicionamiento, alineamiento o PageRank. Cuantas más veces aparezca enlazada una página web, mayor será su importancia y relevancia. Esta idea es similar a la que se utiliza dentro de la comunidad científica que ofrece una mayor relevancia a las obras y autores que son más citados y referenciados por otros autores y en otras obras distintas.
Existen 2 parámetros que condicionan el posicionamiento de las páginas web en los resultados que ofrece un buscador: relevancia y popularidad. Se denomina relevancia a la importancia que tiene una página con respecto al criterio de búsqueda introducido en la consulta. Los motores de búsqueda muestran los resultados ordenados por relevancia de mayor a menor. Por su parte, por popularidad se mide bien por medio de la cantidad de visitas que recibe una web, o bien mediante la cantidad de enlaces que apuntan hacia esa web.
La tendencia actual es primar la popularidad, pero sin olvidar la relevancia de las páginas que enlazan a la web referente a las mismas palabras clave. Por otro lado, para determinar la relevancia y la posición, cada vez se tiene más en cuenta la calidad y origen de los enlaces frente a la cantidad para mostrar los resultados ordenados de una búsqueda.
Algunos buscadores como Google, tienen en cuenta el texto que sirve de anclaje de inicio como una inferencia para calcular la relevancia de la página de destino. Esto ha conducido a que muchos internautas utilicen esta funcionalidad con el fin de obtener resultados curiosos o jocosos, puesto que si muchas páginas apuntan como destino a un término -aunque este no conste en el propio documento enlazado- se considera que éste es enormemente relevante en dicha materia. Así, si como anclaje de inicio de un enlace se utiliza la palabra "ladrones" y como destino, se toma la URL de la Sociedad General de Autores y Editores, se considera que la SGAE es una autoridad en la materia, aunque la SGAE no contenga la palabra "ladrones" en ninguna de sus páginas.
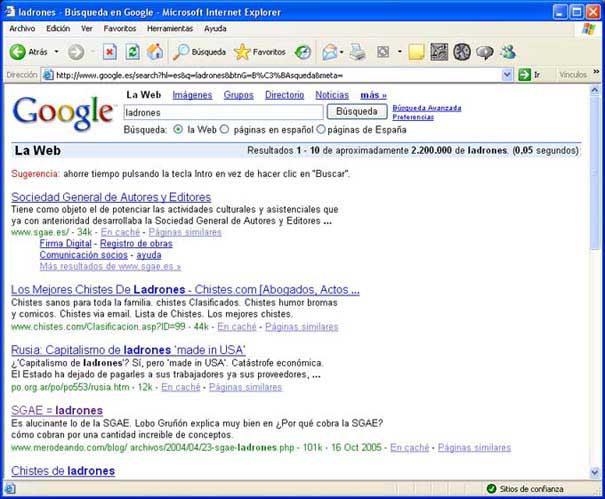
Resultados obtenidos tras la consulta:
ladrones en el buscador Google:
http://www.google.es
Los algoritmos utilizados para mostrar las páginas de resultados se pueden agrupar en 3 tipologías fundamentales:
los que usan el modelo de espacio vectorial: este modelo fue desarrollado por Gerald Salton y se utiliza tanto para indizar documentos como para resolver las consultas. Se basa en la frecuencia de aparición de los términos. El modelo de espacio vectorial, muy utilizado en matemáticas, consiste en que las distancias y las direcciones entre palabras y frases extraídas del texto se miden en un espacio multidimensional. Cada documento o consulta se representa con un vector en un espacio n-vectorial. Esta dimensión viene determinada por el número de términos únicos en el cuerpo del documento. Las palabras significativas se eliminan del vector y se incluyen en un listado de palabras vacías para reducir el porcentaje de palabras con mayor frecuencia de aparición. Después, se asignan pesos a los términos para indicar el grado de importancia en la representatividad del documento. Lo corriente es asumir que la importancia de un término es proporcional al número de documentos en los que aparece ese término. Por último, se aplica el coeficiente de similaridad, esto es, los vectores de dos documentos se encontrarán más cercanos si tienen más términos en común.
los que usan el modelo booleano: con este modelo se plantea la presencia/ausencia de términos sin tener en cuenta el contexto. Se considera que las relaciones entre conceptos pueden expresarse como relaciones entre conjuntos y, de esta forma, las ecuaciones de búsqueda pueden transformarse en ecuaciones matemáticas que ejecutan operaciones sobre esos conjuntos, lo que da como resultado otro conjunto. Los operadores booleanos, al combinarse, permiten hacer búsquedas complejas.
los que usan el modelo hipertextual basado en la conectividad de los enlaces: este modelo tiene en cuenta la propia estructura hipertextual y se basa no sólo en el recuento de enlaces, sino también en el análisis de estos y las relaciones que establecen. Además, cada vez es más común tener en cuenta la calidad y origen de estos.
Estas tipologías no son excluyentes y muchos motores de búsqueda combinan estos modelos.
Ninguno de los principales buscadores presentes en Internet es capaz de indizar los millones de páginas que pueblan la red. Además, cada uno de ellos ofrece funcionalidades y características distintas, por lo que la elección de utilizar uno u otro se deberá basar en preferencias relacionadas con las opciones de búsqueda que ofrezcan, capacidad para búsquedas avanzadas, preferencias en el diseño y funcionalidades de las interfaces de consulta y resultados, si ofrecen herramientas de ayuda para realizar las consultas, grado de exhaustividad, pertinencia, refinamiento y cobertura, frecuencia en la actualización de la base de datos, descripción y resumen de páginas que ofrezcan, agilidad en la muestra de resultados, etc. También hay que tener en cuenta que, además de los buscadores generalistas, existen una serie de buscadores especializados que ofrecen resultados adaptados a áreas concretas y específicas de búsqueda.
En general, se pueden dar una serie de reglas para utilizar uno u otro tipo de buscador:
Para búsquedas de información generalistas: índices temáticos.
Para búsquedas de información concretas: motores de búsqueda o buscadores especializados.
Si se conoce el país donde radica la información: utilizar buscador nacional.
Si se conoce el título, partes del título o palabras clave: motores de búsqueda, ya que muchos de ellos permiten la acotación por estos parámetros o la utilización de operadores booleanos.
Para buscar páginas personales: motores de búsqueda, ya que muchos índices no permiten incluirlas y lo común es que los usuarios tampoco lo hagan.
Para localizar páginas de empresas, organismos e instituciones: índices temáticos.
Si se trata de un archivo que no está en formato HTML: buscadores especializados para Imágenes, Audio, Noticias, Blogs, Listas de distribución, etc.
En resumen, el análisis de los distintos motores de búsqueda debe hacerse teniendo en cuenta diferentes perspectivas:
Métodos de creación de la base de datos y uso de indizadores
Actualización de las bases de datos
Niveles de profundidad en la indización
Diferentes niveles de cobertura del contenido de la WWW
Diferentes niveles y procesos de indización
Diferentes algoritmos de recuperación
Respuestas en formato HTML
Diferentes interfaces de usuario
Diferentes interfaces de interrogación
Pertinencia frente a ponderación de términos
En cuanto a la utilización de buscadores para un hipertexto fuera de la red, existen numerosas herramientas y aplicaciones disponibles para crear nuestra propia herramienta de búsqueda. Una exhaustiva lista de herramientas de búsqueda para webs e Intranets se puede encontrar en Search Tools Products Listings in Alphabeticarl Order: http://www.searchtools.com/tools/tools.html
![]() ABCdatos.
Los buscadores y sus secretos.
http://www.abcdatos.com/buscadores/
ABCdatos.
Los buscadores y sus secretos.
http://www.abcdatos.com/buscadores/
![]() AGUILAR GONZÁLEZ, Rogelio. Monografía sobre motores de
búsqueda. Yahoo, Geocities, 2002.
http://www.geocities.com/motoresdebusqueda/introduccion.html
AGUILAR GONZÁLEZ, Rogelio. Monografía sobre motores de
búsqueda. Yahoo, Geocities, 2002.
http://www.geocities.com/motoresdebusqueda/introduccion.html
![]() BOSWELL,
Wendy. Web Search.
http://websearch.about.com/
BOSWELL,
Wendy. Web Search.
http://websearch.about.com/
![]() CANDEIRA, Javier. "La web como memoria organizada: el hipocampo colectivo de
la Red". En Revista de Occidente, Nº 239, marzo 2001.
CANDEIRA, Javier. "La web como memoria organizada: el hipocampo colectivo de
la Red". En Revista de Occidente, Nº 239, marzo 2001.
![]() CHANG, G. et al. Mining the World Wide Web:
An information
search approach. Norwell, Massachusetts, Kluwer Academic Publishers, 2001.
CHANG, G. et al. Mining the World Wide Web:
An information
search approach. Norwell, Massachusetts, Kluwer Academic Publishers, 2001.
![]()
![]()
![]() CODINA,
Lluís y PALMA, María del Valle. "Bancos de imágenes y sonido y motores de
indización en la www". Revista Española de Documentación Científica, Vol.24,
núm.3, 2001.
http://www.cindoc.csic.es/redc/redc.html
CODINA,
Lluís y PALMA, María del Valle. "Bancos de imágenes y sonido y motores de
indización en la www". Revista Española de Documentación Científica, Vol.24,
núm.3, 2001.
http://www.cindoc.csic.es/redc/redc.html
![]() DÍAZ
FERREIRA, Miguel Ángel. "Los secretos de los buscadores: qué son y cómo
funcionan". iWorld, noviembre, 1997.
DÍAZ
FERREIRA, Miguel Ángel. "Los secretos de los buscadores: qué son y cómo
funcionan". iWorld, noviembre, 1997.
![]() Infobuscadores.com
http://www.infobuscadores.com/
Infobuscadores.com
http://www.infobuscadores.com/
![]() LÓPEZ
FRANCO, José Manuel. Integración de tecnologías a través de servidores
web.
http://trevinca.ei.uvigo.es/~txapi/espanol/proyecto/superior/memoria/memoria.html
LÓPEZ
FRANCO, José Manuel. Integración de tecnologías a través de servidores
web.
http://trevinca.ei.uvigo.es/~txapi/espanol/proyecto/superior/memoria/memoria.html
![]() LÓPEZ
YEPES, Alfonso. "Bancos de imágenes en Internet". Red Digital. Revista
de Tecnologías de la Información y Comunicación Educativas, núm. 3, enero 2003.
http://reddigital.cnice.mecd.es/3/firmas_nuevas/informes/infor_yepes_res.html
LÓPEZ
YEPES, Alfonso. "Bancos de imágenes en Internet". Red Digital. Revista
de Tecnologías de la Información y Comunicación Educativas, núm. 3, enero 2003.
http://reddigital.cnice.mecd.es/3/firmas_nuevas/informes/infor_yepes_res.html
![]() MALDONADO MARTÍNEZ, Ángeles; FERNÁNDEZ SÁNCHEZ,
Elena. Evaluación de los principales ‘buscadores’ desde un punto de vista
documental: Recogida, análisis y recuperación de recursos de información. En
FESABID VI Jornadas Españolas de Documentación. http://fesabid98.florida-uni.es/Comunicaciones/a_maldonado/A_Maldonado.htm
MALDONADO MARTÍNEZ, Ángeles; FERNÁNDEZ SÁNCHEZ,
Elena. Evaluación de los principales ‘buscadores’ desde un punto de vista
documental: Recogida, análisis y recuperación de recursos de información. En
FESABID VI Jornadas Españolas de Documentación. http://fesabid98.florida-uni.es/Comunicaciones/a_maldonado/A_Maldonado.htm
![]()
Tipos de Buscadores
URL:
http://www.hipertexto.info
Fecha de Actualización:
08/12/2013
Fundación Ricardo Lamarca, Ajedrez y
cultura
http://www.fundacionlamarca.es
Mapa de navegación
/ Tabla de contenido /
Mapa conceptual /
Tabla de documentos /
Buscador /
Bibliografía utilizada / Glosario de Términos /
Índice Temático /
Índice de Autores
![]()
![]()
![]() Search
Engine Blog.
http://www.searchengineblog.com/
Search
Engine Blog.
http://www.searchengineblog.com/![]()
![]() Search
Tools for Web Sites and Intranets. Home Page.
http://www.searchtools.com/index.html
Search
Tools for Web Sites and Intranets. Home Page.
http://www.searchtools.com/index.html![]() TRAMULLAS, Jesús. Localización y acceso a la información:
http://www.tramullas.com/ri/index.html
TRAMULLAS, Jesús. Localización y acceso a la información:
http://www.tramullas.com/ri/index.html![]() TRAMULLAS, Jesús. "Sección 3:
La recuperación de información”. En Introducción a la Documática.
http://tek.docunautica.com/
TRAMULLAS, Jesús. "Sección 3:
La recuperación de información”. En Introducción a la Documática.
http://tek.docunautica.com/![]() TRAMULLAS, Jesús. "Sección 4. Sistemas informáticos de
tratamiento y recuperación de información documental". En Introducción
a la Documática.
http://tek.docunautica.com/
TRAMULLAS, Jesús. "Sección 4. Sistemas informáticos de
tratamiento y recuperación de información documental". En Introducción
a la Documática.
http://tek.docunautica.com/![]() TRAMULLAS, J. OLVERA, Mª D. Recuperación
de la información en Internet. Madrid, Ra-Ma, 2001.
TRAMULLAS, J. OLVERA, Mª D. Recuperación
de la información en Internet. Madrid, Ra-Ma, 2001.![]()
![]() Trucos de
Google, buscadores y gestión documental.
http://trucosdegoogle.blogspot.com/
Trucos de
Google, buscadores y gestión documental.
http://trucosdegoogle.blogspot.com/![]()
![]() Web Indicators Portal.
http://www.webindicators.org/
Web Indicators Portal.
http://www.webindicators.org/![]()
![]()
![]()
Principales Buscadores
Autora: María Jesús Lamarca Lapuente (currículo personal)
34.389 enlaces (10.436 externos y 23.953 internos)
![]()
Creative Commons
Reconocimiento-NoComercial-NoDerivados-Licencia España 2.5.
OTRAS PÁGINAS DE LA AUTORA
![]() Blog
El Cultural a la Puerta::
http://puertadetoledo.blogspot.com/
Blog
El Cultural a la Puerta::
http://puertadetoledo.blogspot.com/ 
Ageteca. Base de Datos de Gestión
Cultural:
http://www.agetec.org/ageteca


Especial Poesía: Hasta allí hemos llegado![]()
digital y
mundo analógico:
http://www.flickr.com/photos/artesadigital/

![]()
|
|
 en línea para que la persona u organización que
quiera darse de alta identifique y clasifique su página web. La mayor parte de
los formularios de alta que ofrecen los distintos buscadores piden unos datos
obligatorios que suelen ser: el título de la página, URL, descripción y
clasificación del recurso; pero también pueden solicitar otro tipo de datos
como descriptores o palabras clave, persona o entidad responsable de la página,
tipo de información (académica, comercial, personal, informativa, etc.),
localización geográfica, idioma, etc. La clasificación tiene como fin la
inclusión del recurso en alguna categoría jerarquizada de las que luego se
presentarán en el índice temático. Los responsables del buscador suelen
analizar y evaluar si la información que provista y el contenido real se
ajustan o no.
en línea para que la persona u organización que
quiera darse de alta identifique y clasifique su página web. La mayor parte de
los formularios de alta que ofrecen los distintos buscadores piden unos datos
obligatorios que suelen ser: el título de la página, URL, descripción y
clasificación del recurso; pero también pueden solicitar otro tipo de datos
como descriptores o palabras clave, persona o entidad responsable de la página,
tipo de información (académica, comercial, personal, informativa, etc.),
localización geográfica, idioma, etc. La clasificación tiene como fin la
inclusión del recurso en alguna categoría jerarquizada de las que luego se
presentarán en el índice temático. Los responsables del buscador suelen
analizar y evaluar si la información que provista y el contenido real se
ajustan o no. ofreciendo la posibilidad de elegir entre búsquedas mediante
clasificación temática o por medio de formularios. Los formularios deben
ofrecer tanto búsquedas sencillas como búsquedas más complejas que permitan
algún tipo de herramientas como truncado de palabras, operadores booleanos, términos
compuestos, acotación de búsquedas, etc. y con diferentes campos de búsqueda
en los que se requiera lenguaje libre o controlado (título, palabras clave,
idioma, localización, tipo de información, etc.). También deben ser capaces
de controlar el vocabulario para deshacer ambigüedades, sinonimias, polisemias,
etc. Además, los sistemas de búsqueda, deben presentar los resultados de la búsqueda
de una forma también flexible permitiendo varios criterios de aparición y
ordenación de los datos y ofreciendo diferentes formatos para que el usuario
elija el que se ajusta a su gusto y necesidades.
ofreciendo la posibilidad de elegir entre búsquedas mediante
clasificación temática o por medio de formularios. Los formularios deben
ofrecer tanto búsquedas sencillas como búsquedas más complejas que permitan
algún tipo de herramientas como truncado de palabras, operadores booleanos, términos
compuestos, acotación de búsquedas, etc. y con diferentes campos de búsqueda
en los que se requiera lenguaje libre o controlado (título, palabras clave,
idioma, localización, tipo de información, etc.). También deben ser capaces
de controlar el vocabulario para deshacer ambigüedades, sinonimias, polisemias,
etc. Además, los sistemas de búsqueda, deben presentar los resultados de la búsqueda
de una forma también flexible permitiendo varios criterios de aparición y
ordenación de los datos y ofreciendo diferentes formatos para que el usuario
elija el que se ajusta a su gusto y necesidades.