María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen.
|
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. |
|
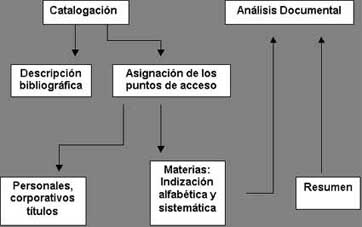
El
catálogo tradicional ha sido el instrumento bibliográfico por antonomasia. Para elaborar el
catálogo,
se partía de la descripción del documento (la llamada
Descripción
Bibliográfica), se elegían los puntos de acceso (personales, corporativos, títulos,
temáticos y sistemáticos) y se añadía la transcripción de los datos locales (signatura y
registro), con el fin de localizar su ubicación física dentro de la biblioteca.
La localización es lo que distingue a un
catálogo de una
bibliografía, ya que el catálogo se reduce y concreta a los documentos existentes
en una biblioteca o centro de documentación determinados. Si la catalogación
se ha centrado en la localización y descripción del soporte
documental, el llamado análisis documental se centraba en el contenido.
Operaciones técnicas que se realizan con el documento Los llamados tradicionalmente puntos de acceso temáticos son el producto de la indización. Indizar es, simple y llanamente, registrar ordenadamente datos e informaciones para elaborar su índice con vistas a una posterior búsqueda y recuperación de la información. Se puede considerar la indización como una operación dirigida a representar, por medio de un lenguaje documental o natural, los datos resultantes del contenido intelectual del documento. La indización se encuentra, por tanto, en el punto de unión entre la catalogación como creadora de puntos de acceso temáticos al catálogo y el análisis documental, esto es, la descripción del contenido intelectual del documento. Por tanto, la relación entre catalogación y análisis documental se produce por los indización (tradicionalmente, por los llamados Puntos de Acceso por Materias) que en las bibliotecas y centros de documentación muy especializados exigían ya un mayor nivel de nivel de profundidad y diversidad, debido a las exigencias de los propios lenguajes documentales y a las necesidades de los propios usuarios de estos centros. En estos centros se exigía no sólo el manejo de catálogos convencionales (encabezamientos de materias y clasificaciones), sino también de bases de datos documentales como tesauros y ontologías. Por su parte, existían un conjunto de normas estandarizadas como la norma ISO 5963:1985 "Methods for examining documents, determining their subjects, and selecting indexing terms", que establece los métodos para examinar documentos, determinar sus temas y seleccionar los términos de indización; o las correspondientes normas ISO sobre redacción de tesauros monolingües y multilingües. Los lenguajes documentales han existido, desde que existen
documentos escritos, como un método de clasificación, almacenamiento,
búsqueda y
recuperación de la información.
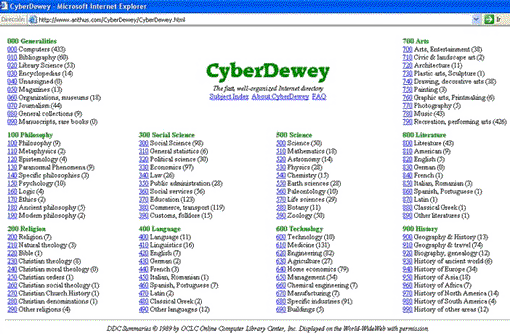
Desde Aristóteles (siglo IV a. C.) hasta las grandes clasificaciones de finales
del siglo XIX (Clasificación Decimal Universal
de Dewey (DDC), Biblioteca del Congreso (LCC),
Clasificación facetada de Ranganathan, etc.) y las desarrolladas a
lo largo de todo el siglo XX como la utilizada por la
Pero además de la descripción formal del documento y del análisis del contenido, existe una tercera función relacionada con la metainformación de un documento, se trata de la función referencial. Esta función se ha llevado a cabo, tradicionalmente, mediante la elaboración bibliografías o listas de referencias. La aparición del hipertexto ha abierto la posibilidad de establecer una red de referencias bibliográficas y documentales mediante la conectividad que permiten los enlaces que es la que establece la posibilidad de no sólo relacionar información, sino también tener acceso a ella. Teóricamente, esta red hipertextual de documentos relacionados no tiene límites y, debido al gran volumen de información en ella contenido, la World Wide Web se ha convertido en el principal repositorio de recursos de referencia en línea, una enorme enciclopedia de acceso universal e inmediato. En la Web, la tradicional separación entre documentos primarios, secundarios y terciarios se rompe, ya que se desdibujan las fronteras entre estos 3 tipos de documentos, pues el hipertexto permite la creación de documentos que soportan estas tres funciones a la vez y el acceso directo tanto a los documentos originales, como a sus referencias, documentos relacionados, listas de referencias, sumarios, directorios, etc. La utilización de metadatos para los recursos digitales ha venido, en parte, a sustituir las tradicionales labores de catalogación y clasificación, ya que se trata de una nueva forma de describir los recursos digitales en línea. Sin embargo, no se puede hablar de una evolución en el sentido de una superación de unas técnicas por otras, puesto que cada método tiene sus aplicaciones. Los lenguajes de clasificación se usan tanto en las bibliotecas generalistas y enciclopédicas para ordenar las colecciones impresas siguiendo las grandes ramas del saber, como en las bibliotecas y centros de documentación especializados con el fin de elaborar índices y sumarios bibliográficos, boletines analíticos, etc. por medio de las entradas de materias o temáticas. Y, de igual forma, estos lenguajes de clasificación pueden ser aplicados a los documentos de la Web.Por su parte, los tesauros se utilizan para producir índices y bases de datos, y para la indización mediante descriptores que permitirán la búsqueda y recuperación de los documentos previamente indizados, lo que favorece unas búsquedas mucho más precisas gracias al uso de un lenguaje controlado. Los lenguajes libres y las listas de palabras clave, aunque transcienden las restricciones de los tesauros, priman la exhaustividad sobre la precisión y son útiles para búsquedas amplias. La indización automática y los sistemas expertos, junto con el desarrollo de una serie de lenguajes semánticos legibles por máquina (OWL, Topic Maps, XFML, etc,) y el uso de bases de conocimiento y ontologías que definen una semántica para construir documentos estructurados basados en XML, suponen también una evolución y no una sustitución de unos métodos por otros, y en muchos casos, todos estos métodos contribuyen y cooperan dentro de un sistema integrado de recuperación y búsqueda, sea en línea o fuera de ella.
Sin embargo, lo que es cierto es que la aparición del hipertexto y, más concretamente de la
Web, sí ha
supuesto una verdadera revolución en las labores de documentalistas y
bibliotecarios. Los recursos digitales presentan características y problemas
concretos que les alejan de los documentos en soportes
tradicionales. Por un lado está el problema de la localización puesto que el
documento puede tener varias localizaciones, diferentes modos y
condiciones de acceso, etc. por otro, existen problemas relacionados con el
formato ya que un mismo documento puede aparecer en varios
formatos de archivo distintos: HTML,
PDF, ASCII, etc., y otro problema añadido es la falta
de estabilidad de los documentos en línea, ya que suelen ser muy volátiles,
se mueven o cambian de sitio o, incluso, desaparecen sin previo aviso. De esta
forma, han surgido numerosos esfuerzos para normalizar
aspectos referidos tanto a la localización e
identificación de los documentos, como a la
Los sistemas de organización del conocimiento, más conocidos por sus siglas en inglés SKO (Systems of Knoledge Organization) son mecanismos que sirven para organizar la información, gestionarla y recuperarla ya sea fuera de la red o dentro de ella. Cualquier biblioteca, centro de documentación o unidad documental que se precie, posee un sistema de organización propio basado bien en en algún sistema normalizado ya establecido, bien en un sistema hecho a medida e, incluso, puede combinar varios de estos sistemas (por ejemplo, utilizar la Clasificación Decimal Universal (CDU) junto con un tesauro o utilizar un esquema desarrollado para la Intranet corporativa local). De forma general, se pueden establecer 4 tipos principales de sistemas de organización del conocimiento:
Al igual que para los documentos en soportes tradicionales existen distintos niveles de descripción del contenido, como también distintas maneras y diferentes herramientas para hacerlo -más o menos formalizadas-, en la Web también podemos aplicar y utilizar dichas herramientas. Todas ellas sirven para facilitarnos la elección de los términos para indizar, clasificar y recuperar un documento en la red y fuera de ella. El término puede ser una palabra única o una frase. A la hora de elegir los descriptores o palabras clave para describir un documento de la Web, podemos hacer una primera distinción entre:
Si elegimos una indización controlada, hay que destacar las siguientes herramientas o conjuntos cerrados de donde extraer los términos:
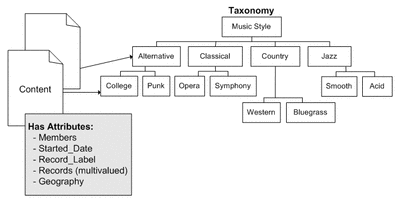
Un ejemplo de taxonomía y Uso de la
taxonomía en metadatos. Para la construcción de estas herramientas de indización (tesauros, ontologías, taxonomías, etc), existen numerosos paquetes de software y aplicaciones tanto gratuitas como de pago. Por ejemplo, Tim Craven-Freeware http://publish.uwo.ca/~craven/freeware.htm ofrece varios programas, entre ellos un extractor de palabras y frases, un indizador de cadenas de texto, un asistente para la escritura de resúmenes, un asistente para la creación, modificación y gestión de tesauros, y un indexador de documentos de la Web.
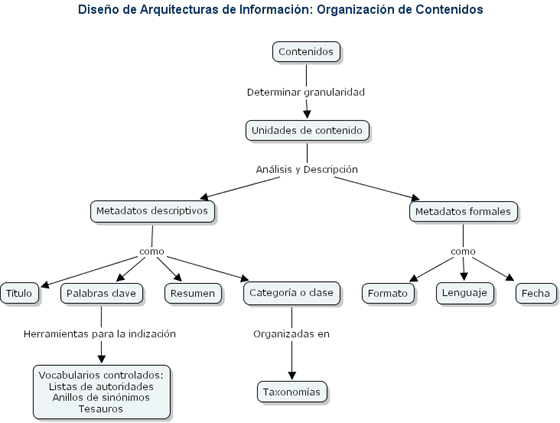
Fuente: Thesaurus Builder. http://www.thesaurusbuilder.com/ Por su parte, Cristòfol Rovira nos ofrece un interesantísimo mapa conceptual sobre metadatos, taxonomías, ontologías y mapas conceptuales que resume todas estas herramientas. El uso de estas herramientas permite que los datos y la información puedan ser comprendidos por los ordenadores sin necesidad de intervención humana, de forma que los agentes web puedan tratar las páginas de manera automática o semiautomática. Los metadatos ayudan a estructurar el contenido de la información, pero las herramientas anteriores, hacen posible una semántica para construirlos. Debida a la ingente cantidad de información existente en la World Wide Web, para poder recuperar la información de forma precisa no sólo es necesario el uso de metadatos siguiendo un esquema común y normalizado para algún dominio del conocimiento determinado, sino que además es preciso otro tipo de información adicional que permita hacer inferencias lógicas y deducciones sobre dicha información. Este es el objetivo que persigue la construcción de la llamada Web Semántica. Para la organización de los contenidos se suele hablar de un proceso que abarca distintas etapas: análisis, descripción, indización y clasificación. Este proceso, como muestran Y. H. Montero y A. Núñez Peña en Diseño de Arquitecturas de Información, se puede representar de la forma siguiente:
Fuente:
MONTERO,
Yusef Hassan. NÚÑEZ PEÑA, Ana. Diseño de Arquitecturas de Información: La granularidad se refiere al nivel de especificidad del contenido descrito, es lo que en esta tesis hemos denominado profundidad al hablar de la gradualidad del hipertexto, esto es, el número de nodos o ramas que cuelgan del nodo raíz según vamos descendiendo verticalmente (en contraposición a la extensibilidad que es el número de hojas o ramas dispuestas horizontalmente). Así pues, cuanto más granular, más específico. Como muestra la figura anterior, centrándonos en una unidad de contenido, Montero y Núñez Peña distinguen 2 tipos distintos de metadatos: metadatos descriptivos y metadatos formales. Según estos autores, los primeros tendrían por objeto facilitar la recuperación de información por parte del usuario (título, palabras clave, resumen, categorías, etc.) y los segundos se referirían mas bien a la gestión de dichos contenidos (formato, lenguaje, fecha, etc.). Otros autores llaman a estos últimos metadatos administrativos. De cualquier forma, las clasificaciones de tipos de metadatos son múltiples y variadas. Para los autores anteriormente citados, "indizar comprendería la tarea de catalogar y describir los recursos a través de palabras clave que forman parte de un índice terminológico o vocabulario controlado." De cualquier forma, la calidad de la indización, según la norma ISO, se mide con 4 parámetros:
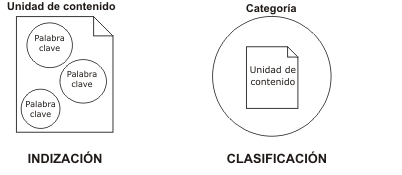
Por otro lado, existen problemas terminológicos a la hora de distinguir entre lo que se entiende por clasificación y lo que se engloba bajo el término de indización. A este respecto, Montero y Núñez Peña afirman: "La distinción entre palabras clave y categorías – y por tanto entre indización y clasificación – es una distinción formal. Mientras que las palabras clave asociadas a una unidad de contenido representan sus conceptos más significativos, la categoría asociada describe el tema principal bajo el que se engloba la unidad de contenido. Una unidad de contenido podría pertenecer a más de una categoría, aunque esta forma de clasificar haría más difusa, todavía, la diferencia entre categorías y palabras clave. Las categorías y sus relaciones se organizan en lo que en el entorno de la Arquitectura de la Información se suelen denominar taxonomías de categorías".
Fuente:
MONTERO,
Yusef Hassan. NÚÑEZ PEÑA, Ana. Diseño de Arquitecturas de Información: De cualquier forma, la clasificación e indización de documentos en Internet se puede realizar de forma manual o automática, utilizando distintas herramientas como motores de búsqueda, robots o agentes inteligentes, y por medio de un trabajo individual o cooperativo aprovechando las ventajas de la red (como hacen las folksonomías) o fuera de ella. Veamos los métodos y herramientas más habituales: Listas y directorios manuales: a la manera de una base de datos o un catálogo tradicionales. La selección de los epígrafes de clasificación se puede dejar o bien en manos del usuario que incluye su documento en el sistema, o bien en manos de indizadores al servicio del mismo. Si los mecanismos no son muy ágiles para hacer un seguimiento de los cambios de contenido o de localización, estas listas y directorios se convierten pronto en obsoletas. Los principales buscadores y portales de acceso a Internet, además de recopilar datos de forma automatizada, también suelen ofrecer un directorio en el que permiten que sean los propios autores de páginas web los que indicen las páginas de acuerdo con unas categorías prefijadas. El Open Directory Project (ODP) http://dmoz.org/ con el que colabora también Google, se anuncia como el directorio web más grande el mundo construido por seres humanos y realizado por editores voluntarios. ODP muestra un directorio de categorías y subcategorías con una descripción de cada una de ellas y permite que los autores o quienes quieran sugerir un sitio web, accediendo paulatinamente desde las categorías generales a las más específicas, incluyan dicha web en la categoría correspondiente.
Fuente: Open Directory Projetc. http://dmoz.org/ Bases de datos de recopilación automática: la puesta en marcha y popularización de la World Wide Web condujo, ya desde sus inicios, al desarrollo de una serie de aplicaciones y herramientas que hicieran posible no sólo la navegación, sino también la recuperación de información de forma directa y automática. De esta forma, nacieron los primeros buscadores con sus robots de recuperación que ofrecían una mayor rapidez, actualización y especificidad en la indización para confeccionar enormes bases de datos y permitir el acceso a sus registros. Los buscadores más populares en los inicios fueron Yahoo, AltaVista (1995) y Lycos (1994). El primer metabuscador fue MetaCrawler nacido en 1994 a raíz de un Seminario en el Department of Computer Science and Engineering de la Universidad de Washington y se lanzó al público en 1995, cuando ya agrupaba el acceso combinado a Galaxy, InfoSeek, Lycos, WebCrawler, Yahoo y OpenText. Actualmente, todos los grandes buscadores de Internet construyen sus bases de datos usando robots, esto es, programas que recorren automáticamente la Web y extraen palabras clave, metadatos, enlaces, etc. Sin embargo, en los primeros tiempos, al no existir metadatos ni marcas, era necesario extraer la información del propio texto y, por lo tanto, no todos los documentos de la Web eran legibles por este tipo de programas. Hasta fechas muy recientes, por ejemplo, no se indizaban ni las imágenes ni los archivos pdf o los PostScript. El método más utilizado por estos rastreadores de la Web, es el llamado "localización-frecuencia", que consiste en que para calcular la relevancia de un término se le asigna un valor relacionado con la frecuencia con que éste aparece en el texto del documento o inversamente relacionado con su frecuencia total en el índice global de la base de datos. Existe también un factor de corrección que se refiere al lugar de aparición del término, dándole mayor importancia si el término aparece en el título, en la cabecera, o al principio del documento. El crecimiento desmesurado de la bases de datos de los buscadores y la tendencia a la publicidad comerciales, ya que muchas empresas pagan por aparecer en los primeros puestos del ranking, exigen cada vez más perfeccionar los mecanismos para que las búsquedas sean más precisas y exhaustivas. Sistemas distribuidos con indización asistida: se trata de un modelo que parece conjugar lo mejor de los procedimientos manuales y los automáticos y que alcanza un mayor perfeccionamiento con los formatos normalizados de metadatos. Como era imposible catalogar, indizar y elaborar resúmenes para todos los documentos que existían en la red, en el primer encuentro sobre control de contenidos de recursos distribuidos en Internet mediante metadatos, celebrado en Dublín (Ohio) del 3 al 5 de marzo de 1995, se acordó que fueran los autores y los proveedores de información -esto es, los responsables del documento- los que proporcionaran la descripción de los recursos que ofrecían los documentos. Nació así Dublín Core Metadata Initiative, una entidad que establece una de las normas más utilizadas y estandarizadas para la descripción del contenido de los documentos. Nacen así las etiquetas <META> incrustadas en HTML para la descripción del contenido del documento. Se trata de un modelo a medio camino entre la simplicidad de un índice normal y la complejidad de un registro catalográfico tradicional. Los metadatos son valores que se presentan asociados a su carga semántica, expresada por la unión de un elemento estructural (autor, título, fecha...) y las variables correspondientes. Se ha producido un proceso de normalización en el tiempo en el que ha sido necesaria tanto la colaboración de los grandes proveedores de información (como los grandes editores electrónicos), como de quienes establecen las distintas versiones y reglas de los lenguajes de marcas o de los desarrolladores de programas para hacer páginas web. Existen sistemas automatizados que transforman los distintos formatos normalizados de descripción y los valores de catalogación a otros esquemas de metadatos. HTML, XML u otros SGML deben hacer posible la inclusión de los conjuntos de metadatos en los documentos para su reconocimiento por los motores de búsqueda. Los sistemas más corrientes de recuperación automática (AltaVista, Excite, MetaCrawler, Google, Lycos, etc.) no sólo toman las palabras clave del título, sino que también toman las etiquetas <META> para indizar las páginas web, para presentar los resultados de búsqueda y para recopilar la información o calcular la relevancia. De esta forma, las palabras clave en forma de metaetiquetas se pueden ubicar en la cabecera del código HTML entre las etiquetas <HEAD> y </HEAD> donde se añaden valores que especifiquen la información sobre el documento, esto es, la descripción mediante palabras (o frases) clave (keywords) de la página, para que éstas puedan ser utilizadas por los robots a la hora de indizar las páginas. Lo normal es utilizar diferentes palabras clave para cada página, para que las distintas páginas del sitio web no aparezcan indiscriminadamente. Desde el punto de vista de un robot que indexa, no es lo mismo PERRO que perro, perros, perras, o perro pastor. <HEAD> Como se ha afirmado anteriormente, para la elección de los términos de metadatos pueden utilizarse descriptores o palabras clave de forma libre, pero lo más efectivo es utilizar esquemas de metadatos normalizados y vocabularios controlados (listas de términos, taxonomías, tesauros y ontologías). Existen una serie de criterios para que una página web pueda ser indexada de forma automática por los buscadores Los buscadores rastrean en la cabecera de los documentos para extraer las etiquetas <META NAME="KEYWORDS"> y <META NAME="DESCRIPTION"> incrustadas en HTML -lo que se ha denominado metadatos en HTML-, pero lo más efectivo es utilizar metadatos en lenguaje XML, por medio de otros lenguajes formales estructurados como RDF y RDFS, Topic Maps, XFML, OWL, etc. que permiten una descripción semántica más estructurada y legible por máquina. Folksonomías: Más recientemente han surgido las llamadas folksonomías, esto es, sistemas para clasificar todo tipo de contenidos en colaboración: enlaces, noticias, canciones, fotografías, correos electrónicos, artículos, etc. Consiste en la creación de un sistema de categorización no jerárquico compartido por una comunidad o red social, de ahí el neologismos folksonomía o clasificación social de contenidos. Se comienza por una etiqueta que crea una persona y que se convierte en una categoría de uso común y colectivo para otras muchas personas. Así, se van poniendo etiquetas simples en un espacio de nombres sin jerarquías ni relaciones de parentesco, dentro de lo que se ha denominado software social. Se trata, pues de taxonomías populares que van configurando nexos entre los usuarios y redes sociales para almacenar información. Como afirma la enciclopedia Wikipedia (http://es.wikipedia.org/wiki/Folksonomía) que utilizar el término con c y no con k, etimológicamente, folcsonomía significa "clasificación gestionada por el pueblo" (folk= pueblo; nomos= ordenar, gestionar). Al realizar una folksonomía, varios usuarios colaboran en la descripción de un espacio informativo para establecer una lista de palabras clave, o un vocabulario no controlado. La diferencia entre una taxonomía y una folksonomía se basa en que en ésta última se realiza un intercambio de opiniones. Desde el punto de vista de los usuarios, el tagging (de tag, marca o etiqueta) genera una navegación basada en la exploración. Los tags sirven para clasificar, ordenar, buscar y encontrar información de distintos tipos y ya hay muchos sistemas de búsqueda por marcas de este tipo que se usan en aplicaciones de software social como los siguientes:
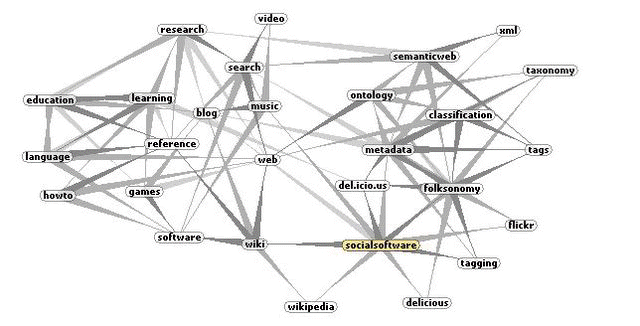
Un directorio categorizado de colecciones de etiquetas de este tipo organizadas por sitios, organizaciones, actividad, lugar, tecnología, etiquetas, fecha, etc. se puede consultar en: http://www.siderean.com/facetious/facetious.jsp No cabe duda del valor social de este tipo de etiquetas para determinados grupos sociales, sin embargo, la falta de un vocabulario controlado, posiblemente generará numerosos problemas como sinonimias, polisemias, etc. si no se establece un vocabulario más normalizado. Uniendo todas estas redes sociales, se construye así poco a poco, una tagsonomía de la red. En la siguiente imagen se muestra un diagrama de la red de relaciones establecidas a partir de la etiqueta socialsoftware en del.icio.us
Fuente: Antoine's Blog on Business and
Technology. Redes. Existen numerosas herramientas que permiten la construcción de diagramas en red ya que estos permiten una navegación simple en medio de la complejidad de la red. Los métodos de clasificación y categorización mediante etiquetas favorecen esta nueva forma de acceder a los contenidos por navegación mediante una interfaz muy gráfica que dé acceso de forma sencilla a los contenidos que nos interesen. También es posible navegar a través de un grupo de imágenes, como se muestra en los proyectos expuestos en el apartado de metadatos para imágenes donde, a través de una clasificación facetada, es posible utilizar las imágenes jerarquizadas como interfaz de navegación por los propios contenidos. Por su parte, los mapas temáticos son una manera formal para declarar un conjunto de temas y proveer enlaces a documentos o nodos de subdocumentos que tratan esos temas. Utilización de agentes inteligentes, asistentes y otros dispositivos mediadores: Se trata de programas y dispositivos que tienen en cuenta algunas acciones y respuestas de los usuarios, que poseen cierta capacidad de iniciativa y autonomía propias y cierta capacidad de reactividad, puesto que reaccionan o se adaptan a los cambios de un entorno determinado (Véase por ejemplo el juego que se ofrece en 20Q: http://www.20Q.net/). Hay distintos tipos de agentes. De forma genérica, un agente inteligente es el programa que, basándose en su propio conocimiento, realiza un conjunto de operaciones destinadas a satisfacer las necesidades de un usuario o de otro programa. Algunos agentes se sitúan junto a los datos o los recursos que observan, otros generan interfaces que facilitan la comunicación con los usuarios, otros son capaces de transmitirse a través de las redes y de examinar, procesar y comunicar las descripciones de recursos. La tendencia es a la especialización de contenidos y a la aparición de servicios especializados donde se produce una mezcla de intervención humana en la descripción de recursos y la automatización a través de la recuperación automática o el uso de agentes inteligentes. Es preciso definir y estructurar los documentos a través de un lenguaje formal normalizado (como XML) que vaya más allá del mero nivel descriptivo de etiquetas o marcas. El documento debe representarse a través de modelos adecuados de datos y de relaciones con lenguajes que permitan una rica y precisa estructuración semántica y no únicamente mediante la simple recopilación y organización de términos. Es preciso definir los modelos de usuario y elaborar unas bases de conocimiento dinámicas que se ajusten mediante procesos de aprendizaje al perfil informativo de cada usuario y a sus cambios. Lo que prima es el enfoque cognitivo, pues el interés se centra en el usuario y en los estados cognitivos relacionados con la información. Los sistemas deben, pues, enfatizar la representación, análisis y apoyo a los estados cognitivos. Para ello, se precisa una amalgama de especialistas en distintas disciplinas: comunicaciones y proceso de datos; informáticos e investigadores en inteligencia artificial; documentalistas, bibliotecarios y otros especialistas en documentación; lingüistas, productores de información, etc. Para construir la Web Semántica hará falta una infraestructura común y normalizada de aplicaciones, protocolos y lenguajes formales estructurados con capacidad para describir el contenido semántico para que sea legible por máquina y para que los sistemas y los seres humanos puedan interoperar unos con otros y entre ellos. Bibliografía
Indización automática
URL:
http://www.hipertexto.info
Fecha de Actualización:
29/07/2018
Fundación Ricardo Lamarca, Ajedrez y
cultura
Mapa de navegación
/ Tabla de contenido /
Mapa conceptual /
Tabla de documentos /
Buscador /
Bibliografía utilizada / Glosario de Términos /
Índice Temático /
Índice de Autores
| ||||||
|
|