|


 


Los principales buscadores de
Internet construyen sus bases de datos usando robots
comúnmente denominados spiders (arañas), crawlers o webcrawlers. Estos robots son potentes programas que recorren la
Web de
forma automática y buscan textos, a través de los documentos HTML
(u otro tipo de formatos como pdf, imágenes, etc.), donde se
incluyan determinadas palabras. Estos textos, junto con las direcciones
URL que los contienen, son indexados, clasificados
y almacenados en grandes bases de datos para que los internautas,
posteriormente, dirijan allí sus consultas e interroguen a la base de datos
buscando alguna palabra o frase.
Los robots vuelven a recorrer periódicamente
 estas páginas para buscar alguna
modificación o la incorporación de nuevas palabras. Así, la actualización
se realiza de forma automática. En general, los robots comienzan con un listado
de enlaces y
URLs preseleccionadas y, recurrentemente, visitan
los documentos que se referencian desde las mismas. estas páginas para buscar alguna
modificación o la incorporación de nuevas palabras. Así, la actualización
se realiza de forma automática. En general, los robots comienzan con un listado
de enlaces y
URLs preseleccionadas y, recurrentemente, visitan
los documentos que se referencian desde las mismas.
Así pues, en la red hay varios
sistemas de búsqueda e indización basados en robots
software que:
-
recuperan y
procesan todas las páginas web que encuentran
-
extraen
información de referencia (índices) sobre las páginas, esto es, las indizan
-
los índices se almacenan en bases de datos que ofrecen
servicios de búsqueda basados en expresiones y palabras clave
Ejemplos de robots son:
- Gigabot (robot de
Gigablast)
- Googlebot (robot de
Google)
- Mozilla Compatible Agent (robot de
Yahoo)
- Msnbot (robot de
MSN)
De esta forma, podemos definir un robot como un programa que recorre una estructura de
hipertexto recuperando un enlace y todos los enlaces que están referenciados
para, a partir de ahí, alimentar las grandes bases de datos de los
motores de búsqueda de la Web. Por el
contrario, los
Índices y
Directorios suelen formarse de forma manual operados por humanos (o de forma
automática, pero una vez que los humanos han introducido los datos en el índice por categorías y
subcategorías) y no
recuperan automáticamente los enlaces incluidos en las páginas web, sino que
sólo se limitan a hallar lo que las personas previamente incluyen en ellos,
pudiendo como ventaja, clasificar fácilmente por secciones
los temas de las páginas web.
Para ver en la práctica cómo funciona un robot, existe una
herramienta gratuita en la red que simula lo que ve exactamente un buscador
cuando visita una página web. Al introducir una URL, esta herramienta muestra
lo que ve el buscador, la información que éste podría indizar y un análisis de
los enlaces encontrados en la página:
Searh Engine Spider Simulator
http://www.webconfs.com/search-engine-spider-simulator.php
Robots: los robots adoptan numerosas denominaciones. Casi todas ellas
tienen que ver con la metáfora de la Web como telaraña en la que estos robots se
mueven como virus. Sin embargo, lo único que hace un robot es visitar los sitios
y extraer los enlaces que están incluidos dentro de estos.
He aquí los principales tipos y denominaciones de robots:
-
Arañas (Spiders):
es un programa usado para rastrear la red. Lee la estructura de hipertexto y
accede a todos los enlaces referidos en el sitio web. Se utiliza como sinónimo
de robot y crawler.
-
Gusanos (Worms):
es lo mismo que un robot, aunque técnicamente un gusano es una réplica de un
programa, a diferencia de un robot que es un programa original. Se usan, por
ejemplo, para duplicar los directorios de FTP para que puedan acceder más
usuarios.
-
Orugas (Web crawlers): es
un tipo específico de robot que ha dado lugar al nombre de algunos buscadores
como Webcrawler y
MetaCrawler.
-
Hormigas (WebAnts):
cooperativa de robots. Trabajan de forma distribuida, explorando
simultáneamente diferentes porciones de la Web. Son
robots que cooperan en un mismo objetivo, por ejemplo, para llevar a cabo
una indización distribuida.
-
Vagabundos (Wanderes): son una clase de robots que realizan estadísticas sobre la Web, como por ejemplo,
número de servidores, servidores conectados, número de webs, etc.
-
Robots de conocimiento (Knowbots): localizan referencias hipertextuales dirigidas
hacia un documento o servidor concreto. Permiten evaluar el impacto de las
distintas aportaciones que engrosan las distintas áreas de conocimiento de la
Web.
Se pueden utilizar robots para diferentes propósitos:
- Indexar
- Validar HTML u otros
lenguajes
- Validar enlaces
- Monitorear "qué hay de nuevo"
- Generar imágenes, mapas, etc.
Una característica importante de los robots es la clase de algoritmos utilizados para:
-
seleccionar los enlaces a
seguir. Se pueden utilizar desde los clásicos algoritmos de búsqueda sin
información (profundidad,
amplitud) hasta cualquier solución compleja basada en
heurística (relevancia, popularidad, etc.).
-
determinar la frecuencia entre visitas.
Existen robots capaces de "aprender'' el intervalo de
actualización de las páginas y así planificar automáticamente sus visitas.
Para ayudar a los robots a indizar las páginas (o a no
indizar ciertas páginas), se pueden utilizan 2 mecanismos diferenciados:
- Crear un archivo de texto (robots.txt) que se ubica
en el directorio raíz y que permite al administrador de un sitio web controlar
el acceso de los robots a su sitio. Por ejemplo:
.../documentos/buscador/robot.txt
-
Utilizar la metaetiqueta "robots". Por
ejemplo: <META NAME>="robots" CONTENT="index,follow">
La etiqueta robots cuenta con 5 atributos que se pueden utilizar: index,
all, follow,
noindex, nofollow.
El atributor index
indica al robot de búsqueda que indice la
página y la añada a la base de datos. El atributo "all" indica que se
indexen todas las páginas. El atributo "follow",
indica que han de seguirse los enlaces que están en la página. Las acciones opuestas son
"noindex" y "nofollow".
Se pueden escribir 2 de estos atributos en la meetiqueta, pero no se permiten 2
atributos opuestos tales como "index, noindex".
También existen otra serie de metaetiquetas para indicarle
al robot determinadas acciones:
-
<Meta NAME="revisit-after"
content="30 day"> Indica cada cuánto tiempo debe el robot visitar la
página para volver a indexarla
-
<Meta http-equiv="Refresh"
content="0;URL=http://www.newurl.com"> Especifica la
URL y el tiempo en segundos para que el navegador la refresque la propia
página o la redireccione a una segunda
Mientras que el uso del archivo robots.txt está estandarizado y
lo utilizan los principales robots, no ocurre lo mismo con las metaetiquetas.
De cualquier forma, hay que tener en cuenta que existen miles de robots
rastreando la red y que muchos de
ellos no respetan estas convenciones, por lo que las indicaciones de acceso o
las instrucciones de restricción de dicho acceso
sólo serán respetadas por aquellos que operen siguiendo la ética de la red.
Estos estándares se pueden consultar en
Robots
Exclusion:
http://www.robotstxt.org/wc/exclusion.html
Cada motor de búsqueda sigue unas
diferentes características de rastreo o crawling (rastreo
profundo, soporte de: marcos, mapas de imágenes, lectura del archivo robots.txt,
metaíndice robot, rastreo de enlaces de popularidad, aprender de la frecuencia,
inclusión de pago, etc.), características de indización (texto completo,
palabras vacías, metadescripción, meta palabras clave, texto alternativo,
comentarios, etc.) y características de clasificación (estímulos de
clasificación por meta-índices, enlaces de popularidad, por aciertos directos,
etc.). También reaccionan de forma distinta ante el uso de técnicas para mejorar
la clasificación, lo que en argot técnico se denominan técnicas de spam,
entre las que destacan: uso de páginas de meta-refresco o redireccionamiento que
conducen a otras páginas; colocar texto invisible al ojo humano, pero legible
por el motor de búsqueda; etc. Muchos robots prohíben el uso de estas técnicas y
directamente no indizan estas páginas, mientras que otros robots no indizan el
texto pequeño porque lo suelen confundir con spam, etc.
The Web Robots
Page (http://www.robotstxt.org/wc/robots.html)
ofrece una completísima información sobre los robots que operan en la Web
y ofrece una
lista exhaustiva de robots y una
base
de datos por tipos de robots con las principales características de cada uno
de ellos: propósito, plataforma de utilización,
contacto, etc.
Si el término robot se presenta confuso
para establecer una definición y una tipología claras, lo mismo sucede con el
término agente, puesto que a veces ambos términos se presentan como sinónimos y,
así, suele utilizarse el término agente dentro de la propia definición de robot
o como un tipo específico de robot. "Robot es un agente
explorador no humano que examina sitios web, siguiendo enlaces de hipertexto
para indexarlos y añadirlos a su base de datos".
Agentes: el término agente fue
empleado por vez primera por Minsky en su obra "The Society of Mind". En el
momento actual, la palabra "agente" tiene muchos significados
distintos, puesto que se utiliza en disciplinas muy distintas. Así,
encontramos agentes referidos a:
-
Agentes autónomos
-
Agentes
biológicos
-
Agentes robóticos 
-
Agentes
computacionales
-
Agentes de
vida
artificial
-
Agentes
de software
-
Agentes de
tareas específicas
-
Agentes de
entretenimiento
-
Virus, etc.
Fuente: STAN, Franklin.
GRAESSER, Art. Is it an Agent, or just a Program? A Taxonomy for Autonomous Agents.
http://www.msci.memphis.edu/~franklin/AgentProg.html
Y cuyas propiedades se pueden resumir de la siguiente forma:
-
Reactivo: Responde a
cambios en el ambiente
-
Autónomo:
Ejerce control sobre sus propias acciones
-
Orientado por
Objetivos: no actúa simplemente en respuesta al ambiente
-
Temporalmente:
Continuo es un proceso que está continuamente ejecutándose
-
Comunicativo:
se comunica con otros agentes, quizá incluyendo gente
-
De aprendizaje:
cambia su comportamiento basado en su experiencia previa
-
Móvil: capaz
de transportarse a sí mismo de una máquina a otra
-
Flexible: las
acciones no corresponden a un libreto tipo script
-
Carácter:
presenta una personalidad y estados
En el campo informático y, de forma general, podemos definir
un agente como un componente software y/o hardware que es capaz de actuar para
realizar tareas en beneficio del usuario.
De forma más específica y siguiendo a
Jesús Olivares, un agente es un sistema de
hardware/software que interactúa con su entorno (u otros agentes o
humanos), guiado por uno o varios propósitos, es proactivo (reacciona a eventos
y a veces se anticipa haciendo propuestas), adaptable (se puede enfrentar a
situaciones novedosas), sociable (se comunica, coopera o negocia) y su
comportamiento es predecible en cierto contexto.
La tipología de los agentes varía de unos autores a otros,
pero lo más común es establecer una tipología basada en 3 características:
cooperativos, autónomos y de aprendizaje. Así, encontramos:
- Agentes Colaborativos: Cooperativos y
Autónomos
- Agentes de Interfaz: Autónomos y de Aprendizaje
- Agentes de
Aprendizaje Colaborativos: Cooperativos y de Aprendizaje
- Agentes Smart:
Cooperativos, Autónomos y de Aprendizaje
Las aplicaciones de los
agentes son muy numerosas, entre las que podemos destacar: uso de agentes en Internet e interfaces
de usuarios, utilización en sistemas de información, juegos y animaciones, comercio
electrónico, educación, etc.
En el ámbito de la Web y, de forma específica, podemos destacar
los siguientes tipos de agentes:
-
Agente autónomo: se trata de un programa que "viaja" entre los sitios web, decidiendo por
él mismo qué debe hacer y
cuándo debe moverse a otros lugares.
Estos agentes sólo pueden viajar entre sitios ubicados en
servidores especiales y no están muy difundidos en el área de Internet.
-
Agente inteligente:
se trata de un programa que ayuda al usuario a ciertas acciones. Por ejemplo, a rellenar
formularios, elegir productos, encontrar determinada cosa, etc. Este tipo
de agentes también se denominan softbot, esto es, software robot. Usa
herramientas de software y servicios basados en el comportamiento de las
personas.
-
Agente de usuario:
es el nombre técnico para denominar a un programa que ejecuta determinadas tareas para un usuario en la
red. Ejemplos son: un navegador como Internet Explorer, o un agente de correo
del tipo Email User-agent, Eudora etc.
El sitio web citado anteriormente:
The Web Robots
Pages cuenta con un apartado llamado
The Web Robots
FAQ que explica numerosas cuestiones sobre las definiciones, funciones y
tipos de robots y
agentes Web.
Jesús Tramullas en
Recuperación de información en Internet afirma que un
concepto claro en la definición de agente es el de cooperación. Este autor
distingue los siguientes tipos de agentes personales:
Los agentes personales aplican los principios de los agentes de software situándose al lado del
usuario, quien les delega sus tareas y actúan en segundo plano. Según Tramullas,
estas tareas sea llevan a cabo por medio de las siguientes fases:
A pesar de que
existen diversas definiciones del término agente inteligente, centrándonos en los sistemas de
ayuda al usuario para la recuperación de información o para ayudarle a este a
realizar tareas simples, los métodos frecuentemente utilizados para el
desarrollo de agentes inteligentes basados en técnicas de
minería de datos (datamining) y
aprendizaje son:
-
Basados en
el contenido: En
este enfoque de clasificación de texto, el sistema busca por ítems similares a aquellos que el usuario quiere, basado en la
comparación de contenido. El enfoque tiene su origen en Recuperación de la
Información, es muy popular en sistemas que trabajan sobre datos de texto como
documentos web o news. Existen problemas concretos cuando se capturan aspectos del contenido, como
música, vídeo e imágenes, e incluso para dominios de texto, pues muchas
representaciones capturan solamente ciertos aspectos de dicho contenido. Algunos ejemplos
de agentes de este tipo son: WebWatcher, Lira, Musag,
Letizia, Personal WebWatcher, CiteSeer, ContactFinder e Internet Fish.
-
Basado en un
enfoque
colaborativo: En contraste con el enfoque basado en el contenido, que puede
ser aplicado a un solo usuario con éxito, el enfoque colaborativo asume que
existe un conjunto de usuarios utilizando
el sistema. Lo que se ofrece al usuario está basado en la reacción de otros
usuarios. El sistema busca por usuarios con intereses similares y recomienda los
ítems que considera que un usuario desearía, esto es, analiza la similaridad entre usuarios y
no entre ítems. Este enfoque se usa, normalmente, para datos no textuales (vídeo o audio, por
ejemplo), aunque también se usa para datos de tipo texto, por ejemplo, filtrado
de news. Está basado en la frecuencia de los temas con que los usuarios
acceden a la información, no en el contenido. Algunos ejemplos de agentes
que utilizan este enfoque son: Firefly (un
agente que funciona en Internet creando un perfil de la persona y hace
sugerencias de música y películas basándose en los gustos similares de las
personas inscritas
http://www.firefly.com), Ringo, Siteseer, Phoaks, GroupLense, Referral Web, Fab, WebCobra
y Lifestyle Finder.
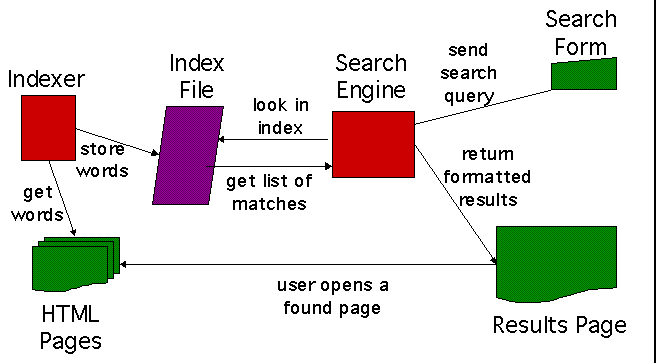
Fuente: Web Admin's Guide to Site Search
Tools.
http://www.searchtools.com/guide/index.html
Existe una forma de saber
si nuestras páginas web han sido visitadas por un robot. Si contamos con
algún servidor de estadísticas y vemos que este muestra que un mismo IP ha accedido a
todas las páginas del hiperdocumento
en un brevísimo lapso de tiempo, es señal de que el visitante es un robot,
ya que esto
 no podría hacerse de forma manual en unos pocos segundos. Otra
forma aún más segura es conocer el nombre propio del servidor que
corresponda a esa IP y si este coincide con alguno de los motores de
búsqueda más comunes que rastrean la red, no hay duda, hemos sido "espiados" e indizados por un motor de búsqueda. no podría hacerse de forma manual en unos pocos segundos. Otra
forma aún más segura es conocer el nombre propio del servidor que
corresponda a esa IP y si este coincide con alguno de los motores de
búsqueda más comunes que rastrean la red, no hay duda, hemos sido "espiados" e indizados por un motor de búsqueda.
A
pesar del desarrollo tecnológico y perfeccionamiento de robots y agentes, el
crecimiento imparable de la Web se ha convertido en un
verdadero problema para las técnicas de indización y búsqueda de la información
en la red y mantener actualizadas las bases de datos
de los buscadores se hace cada vez más difícil. Los
sistemas de indización centralizados no se pueden aplicar a toda la red debido
al enorme tamaño de esta, a los recursos que se precisan para procesar y
almacenar tal volumen de información y al ancho de banda que se consume. Todo
ello conduce a la imposibilidad de que un único robot de indización cubra toda
la Web. Por otro lado, muchos robots web causan tráfico extra y un desperdicio del
ancho de banda porque varios robots recuperan el mismo documento para indizarlo
y actualizarlo. Aunque existen muchas propuestas para resolver este
problema tratándolo desde una perspectiva de red, la única opción, por ahora, es
elegir, en cada caso concreto, el buscador más apropiado para nuestros gustos y
necesidades de información.
Como hecho curioso, a la derecha se muestra una imagen del chat-robot
creado por Ikea que es capaz de responder a casi cualquier pregunta. Lo mejor es
probar a hacerle alguna consulta para ver su funcionamiento.
http://193.108.42.79/ikea-es/flash_files/bot.html
Bibliografía:
 A Brief Introduction to Web Spiders and Agents.
http://it-lahore.tripod.com/web_robots.htm
A Brief Introduction to Web Spiders and Agents.
http://it-lahore.tripod.com/web_robots.htm
ABCdatos. Definiciones de robots de búsqueda.
http://www.abcdatos.com/buscadores/robot.html
 BERROCAL, J.L. FIGUEROLA, C.G. ZAZO, A.F. y otros. "Agentes inteligentes:
recuperación autónoma de información en la web". Revista Española de
Documentación. Vol. 26, nº1, 2003.
BERROCAL, J.L. FIGUEROLA, C.G. ZAZO, A.F. y otros. "Agentes inteligentes:
recuperación autónoma de información en la web". Revista Española de
Documentación. Vol. 26, nº1, 2003.
BotSpot.
http://www.botspot.com/
BRADLEY, Phil. Internet Tools for the Advanced Searcher.
http://www.philb.com/adint.htm

CODINA, Lluis. MARCOS, Mari Carmen. "Posicionamiento web: conceptos y
herramientas". El profesional de la información, v. 14, n. 2,
marzo-abril, 2005.
http://www.mcmarcos.com/pdf/2005_posicionamiento-epi-maq.pdf
LÓPEZ
FRANCO, José Manuel. Integración de tecnologías a través de servidores
web.
http://trevinca.ei.uvigo.es/~txapi/espanol/proyecto/superior/memoria/memoria.html
KOSTER,
Martijn. The Web Robots Pages.
http://www.robotstxt.org/wc/robots.html
OLIVARES, Jesús. Agentes: concepto, aplicaciones y
referencias.
http://www.jesusolivares.com/
[Volver]
OLIVARES, Jesús. Agentes de software: conceptos, aplicaciones y
tendencias.
http://informaticaeducativa.com/recursos/jesus/tutorial1/ |
