
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen.
|
María Jesús Lamarca Lapuente. Hipertexto: El nuevo concepto de documento en la cultura de la imagen. |
| |||||||||||||||||||||||||||||||||||||||||||
|
|
Recuperación en la WWW |
|
|
La información en en la Web se caracteriza por el dinamismo (cambios continuos de contenido) y la volatilidad (cambios de destino de un mismo documento). Al contrario que en los medios tradicionales, la redundancia o publicación repetida de un documento es una constante en Internet, por eso, en la WWW el problema de la recuperación se agrava.
Los principales métodos de recopilación de documentos de la Web se basan en la utilización de:
Listas, Directorios y Catálogos
Bases de datos de recopilación manual o automática (generalmente en soportes digitales como CD-Rom o en línea)
Bases de datos de recopilación automática mediante:
Indización asistida
Utilización de robots y agentes inteligentes
Sin duda, los métodos más rápidos y eficaces de recuperación de documentos de la WWW son los que proporciona la propia Web a través de los buscadores. Los principales tipos de buscadores son los índices temáticos (se trata de catálogos, directorios o buscadores por categorías en línea) y los motores de búsqueda (buscadores por contenido). Muchos de ellos utilizan robots o programas que exploran grandes porciones de la Web y que extraen información de forma automática. Dicha información puede después ser utilizada para alimentar los motores de búsqueda, para efectos estadísticos, para realizar copias de respaldo, etc. e incluso se está desarrollando la utilización de agentes inteligentes.
Hace ya algunos años se desarrollaron los llamados portales o puertas de acceso a Internet, una especie de escaparates que dan acceso a una serie de servicios entre los que suelen encontrarse la posibilidad de utilizar un determinado buscador, además de ofrecer una serie de servicios como noticias, compras en línea, correo electrónico gratuito, foros, chats, listas de distribución, etc.
Antes de adentrarnos en los mecanismos y herramientas que hacen posible la búsqueda y recuperación de documentos o recursos en un hipertexto, es preciso hacer un pequeño repaso sobre qué entendemos por recuperación, búsqueda y acceso al documento. También es preciso hacer mención a los primeros pasos de recuperación que tuvieron lugar en Internet y posteriormente en el gran hipertexto de la Web.
La recuperación de información es el proceso que permite obtener, de un fondo documental, los documentos adecuados a una determinada demanda de información por parte de un usuario. Este proceso engloba el conjunto de acciones referidas a la identificación, selección y acceso a los recursos de información necesarios para resolver el problema del usuario.
Las demandas del usuario pueden hacerse a partir de las propiedades formales del documento como son el título, autor, editorial, fecha de publicación, etc.; pero también pueden hacerse a partir de las propiedades semánticas o del contenido del documento, esto es, de los temas.
El Proceso de recuperación de información (Information Retrieval), según Belkin y Croft, abarca las siguientes fases:
Podemos distinguir entre:
Todas las fases anteriores son susceptibles de tratamiento informático, aunque éste queda claramente enfatizado en las fases 5 (ejecución de las expresiones), 6 (análisis de la pertinencia o no a la cuestión planteada) y 8 (selección y obtención de los documentos).
Y también podemos diferenciar 2 tipos distintos de información a recuperar
Estos 2 tipos de información "data retrieval" (recuperación de datos, RD) e "information retrieval" (recuperación de información, RI), necesitan una gestión y un tratamiento de la información distinto:
Hay pues, hay que diferenciar la recopilación de datos de la recopilación de información, ya que en una primera etapa, ambos procedimientos se confundían.
Según Rijbergen, podemos establecer las diferencias entre recuperación de datos y recuperación de información de la siguiente forma:
| Recuperación de datos | Recuperación de información | |
| Acierto (correspondencia) | Exacta | Parcial, la mejor |
| Inferencia | Algebraica | Inductiva |
| Modelo | Determinístico | Posibilístico |
| Lenguaje de consulta | Fuertemente estructurado | Estructurado o natural |
| Especificación de la consulta | Precisa | Imprecisa |
| Error en la respuesta | Sensible | Insensible |
La estructuración de los datos es siempre más fácil que la estructuración de la información y por tanto, es igualmente más fácil su recuperación.
La recuperación de información, frente a la recuperación de datos, consiste el tratamiento y procesamiento de documentos, no datos o registros.
Según Dominich, podemos establecer los siguiente Modelos para la recuperación de información:
| Modelo | Descripción |
| Modelos clásicos | Incluyen los tres más comúnmente citados: booleano, espacio vectorial y probabilístico |
| Modelos alternativos | Están basados en la Lógica Fuzzy o lógica difusa |
| Modelos lógicos | Desarrollados en la década de los 90, basados en la Lógica Formal. La recuperación de información se entiende como un proceso inferencial a través del cual se puede estimar la probabilidad de que una necesidad de información de un usuario, expresada como una o más consultas, sea satisfecha ofreciendo un documento como "prueba". |
| Modelos basados en la interactividad | Incluyen posibilidades de expansión del alcance de la búsqueda y hacen uso de retroalimentación por la relevancia de los documentos recuperados. |
| Modelos basados en la inteligencia artificial | Bases de conocimiento, redes neuronales, algoritmos genéticos y procesamiento del lenguaje natural. |
Los sistemas de recuperación de información han sido concomitantes al desarrollo de Internet, pero no será hasta el desarrollo de los motores de búsqueda cuando se perfile una verdadera implantación de sistemas que abarquen el ingente volumen de información que proporciona la Web. Estos sistemas combinan la inteligencia artificial, la indización automática y el procesamiento del lenguaje natural. Sin embargo, antes del desarrollo de los motores de búsqueda y de sistemas más sofisticados, la misma forma de la Web basada en un sistema de hipertexto condujo a la importancia de la propia estructura hipertextual como un método valioso de recuperación de información basada en la navegación y exploración.
Siguiendo a Mari Carmen Marcos Mora, podemos establecer 2 tipos de navegación: browsing y clustering. Para esta autora:
Browsing: "Se entiende por browsing el método de acceso a la información consistente en ojear un espacio con el propósito de reconocer objetos en él. Puede realizarse en espacios de una dimensión (una lista) de forma secuencial, o puede tener lugar en un contexto estructurado que contiene relaciones jerárquicas (por ejemplo en forma de árbol) o bien semánticas o asociativas (por ejemplo en forma de mapa). Puede realizarse tanto en contextos analógicos (revisar las estanterías de una biblioteca, por ejemplo) como en contextos digitales (en el seno de documentos de un procesador de texto, en presentaciones multimedia, en la web, etc). En el caso de la web, el browsing implica desplazamientos hipertextuales a través de una estructura en el seno de una misma sede web o entre distintas sedes web. Este caso particular de browsing en la Web suele recibir el nombre de navegación".
Clustering
Como ejemplo de clustering podemos citar el funcionamiento del navegador Vivisimo. Sin embargo, las técnicas de browsing y clustering no son excluyentes, sino que se pueden conjugar, como lo hace el buscador KartOO, que ofrece una representación gráfica en forma de mapa, agrupando por categorías los distintos documentos resultantes de una búsqueda según la cantidad de términos que coinciden en sus textos, muestra las relaciones entre diferentes términos y permite navegar entre ellos.
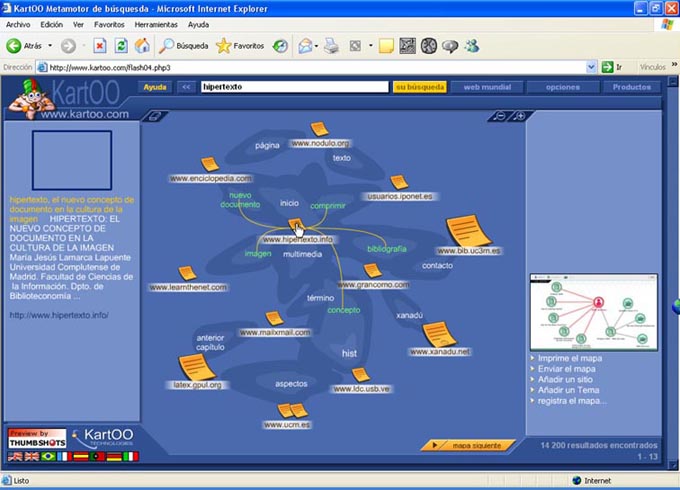
Fuente: KartOO Metamotor de búsqueda (término
buscado: hipertexto).
http://www.kartoo.com
Así pues, las técnicas de recuperación basadas en la navegación, la exploración y el "ojeo" no han sido sustituidas por las técnicas basadas en la interrogación (querying), sino que ambas técnicas coexisten en el espacio y en el tiempo de forma que el usuario puede elegir entre definir previamente el objeto de su búsqueda para realizar una búsqueda directa (búsqueda por interrogación) o puede moverse por una estructura navegacional y decidir sobre la marcha cuál es la información que le interesa a medida que explora la base de datos que se le va mostrando (búsqueda por navegación).
Haciendo un poco de historia, antes de que naciera el primer navegador gráfico Mosaic, hizo su aparición el primer motor de búsqueda en Internet, se trata de ARCHIE, una base de datos con información sobre el contenido de una serie de servidores de FTP que permitía localizar en qué servidor se encontraba un recurso concreto.
También se desarrollaron los sistemas de ayuda VERONICA y WAIS que permitían localizar documentos en un entorno GOPHER. El primero servía para indexar los menús y daba soporte a la navegación hasta que el protocolo gopher:// fue sustituido por el protocolo http con el nacimiento de la World Wide Web, y el segundo permitía explorar diferentes bases de datos y hacer consultas a texto completo utilizando palabras clave. Poco después haría su aparición el navegador Mosaic, que con su interfaz gráfica permitiría un incremento exponencial en el número de usuarios de Internet.
El primer sistema de recuperación de información en la Web fue Yahoo que se convirtió en uno de los sitios más visitados y en un ingente directorio de recursos. Yahoo se gestionaba de forma manual por una serie de personas que analizaban los sitios web, los indizaban y los convertían en registros de un gran directorio. Sin embargo, el crecimiento exponencial de la Web (Nielsen ha calculado que se realizan 550 millones de búsquedas al día en todo el mundo) pronto dejó patente que era imposible utilizar recursos humanos para esta ingente labor, así que comenzaron a desarrollarse los primeros motores de búsqueda que indexaban la información de forma automática.
Además, la consulta de hipertextos por medio de la navegación por la estructura de la red hipertextual es prácticamente imposible en un entorno casi infinito como la WWW, por lo que las técnicas de recuperación han tendido hacia una búsqueda dinámica basada en la búsqueda en línea que traslada la búsqueda a la propia estructura de la WWW y no a los documentos almacenados en índices. Se desarrollaron entonces los llamados lenguajes de consulta a la Web (Web query languages). Existen diferentes modelos de lenguajes de interrogación, pero entre los más comunes destacan un modelo gráfico etiquetado que representa los nodos de las páginas web y los enlaces entre las páginas y un modelo semiestructurado que representa el contenido de las páginas web con un esquema de datos que permanece oculto y que puede ir variando tanto en la extensión como en la descripción. En muchos casos se trata de extensiones de los lenguajes utilizados anteriormente para la construcción y gestión de bases de datos, como el lenguaje SQL (Structured Query Language) para las bases de datos relacionales, pero adaptado al contexto de la World Wide Web.
Todos estos mecanismos permanecen ocultos para el usuario y la interacción entre la persona que consulta y la base de datos se realiza por medio de una interfaz de búsqueda en la que el usuario puede escribir los términos, palabras clave o texto a buscar, para posteriormente recibir los resultados de su consulta por medio de una nueva interfaz de presentación de los datos e información obtenidos como respuesta a dicha consulta.
De esta forma, la interfaz de usuario tanto la diseñada para que el usuario realice la consulta como la que ofrece la respuesta a las operaciones de búsqueda, se ha convertido en un elemento indispensable dentro de los buscadores. Esta interfaz de consulta puede estar compuesta de un simple formulario presentado en una caja de consulta o de un formulario más complejo y sofisticado en una caja compuesta que permita hacer búsquedas avanzadas por medio de la inclusión de una serie de parámetros adicionales que acoten o restrinjan la consulta por medio de operadores booleanos, indicadores de idioma, geográficos, búsquedas dentro del título, dentro del texto, etc.
Sin embargo, esto no resolvía el problema de la abrumadora cantidad de documentos y las miles de referencias que se obtenían tras una búsqueda, por lo que se hizo preciso obtener respuestas más eficaces y pertinentes acordes con las necesidades del usuario. Se trataba del eterno problema o la difícil conjugación entre exhaustividad y precisión. De esta forma, fue preciso no sólo mejorar la interfaz de usuario para facilitar las consultas, sino también aplicar las viejas técnicas de los lenguajes documentales - adaptarlas o crear otras nuevas- para la recuperación en línea.
La manera más fácil para expresar información es en lenguaje natural. Sin embargo, el lenguaje natural es demasiado ambiguo para que el contenido de los documentos sea extractado de forma automática. Para resolver el problema de las ambigüedades en la recuperación de documentos impresos, fue preciso utilizar lenguajes documentales de representación del conocimiento (uso de lenguajes controlados, taxonomías, tesauros, ontologías, etc.). De la misma forma, para recuperar documentos en la Web, se han desarrollado diferentes estrategias, como el uso de metadatos o la utilización de lenguajes semánticos basados en XML (e.j. RDF y OWL) para indizar documentos Web y representar el conocimiento incluido en ellos. Hoy es fácil recuperar la información precisa si se utiliza un lenguaje para representar el contenido semántico de los documentos y soportar las inferencias lógicas. Sin embargo, la mayor parte de los documentos contenidos en la Web carecen de una estructuración semántica.
En resumen, para buscar información en la Web tenemos 3 caminos: seguir un enlace, usar un directorio o usar un motor de búsqueda. Esto es, entre los principales métodos de recuperación de información en la Web podemos destacar:
Búsqueda por navegación o exploración de la red a través de los enlaces de la estructura hipertextual (incluye los lenguajes de consulta a la Web y la búsqueda dinámica).
Directorios (clasifican documentos web por materia y podemos acceder a ellos navegando por los directorios -o índices- y subdirectorios).
Motores de búsqueda (indexan documentos de la Web para que se puedan recuperar a través de una pregunta).
G. Chang en Mining the World Wide Web establece 4 tipos de sistemas de recuperación de información en Web basados en la recuperación de información por medio de palabras clave:
Motores de búsqueda: indexan los documentos o recursos web de forma automática por medio de robots y conforman una base de datos a la que posteriormente consultará el motor cuando se realiza una consulta.
Directorios o Índices temáticos: se trata de listas de recursos organizados por categorías temáticas y estructuradas de forma jerárquica que permiten visualizar los contenidos ofreciendo una lista de enlaces a las páginas que aparecen referenciadas en el buscador.
Metabuscadores: reúnen varios motores de búsqueda ejecutando la consulta en varios motores de forma simultánea y, por tanto, combinan los resultados de diversas fuentes, pero eliminando las referencias duplicadas y agrupando los resultados ordenándolos por pertinencia.
Técnicas de filtrado de información: se trata de un complemento de los motores de búsqueda, y no realmente de un sistema de recuperación distinto. El filtro permite determinar si un documento o recurso es o no relevante a priori para mantenerlo o eliminarlo de los resultados.
Sin embargo, existe numerosas clasificaciones, la mayor parte tiene en cuenta diferentes técnicas usadas en la búsqueda de documentos en la Web, como son:
En cuanto a las técnicas de búsqueda, Chang distingue 5 tipos de búsqueda:
Término simple: se trata de la búsqueda más sencilla en la que el motor de búsqueda mostrará únicamente los documentos en los que aparezca el término.
Término compuesto: este tipo de búsquedas resultan ya más complejas. Para ello los buscadores suelen utilizar la lógica booleana o combinar varios operadores lógicos.
Basadas en el contexto: para esta búsqueda se utilizan los operadores de adyacencia o proximidad con el fin de analizar si los términos aparecen, además de en el propio documento, en la misma frase y en un orden determinado.
Lenguaje natural: es la búsqueda más compleja, pero más simple para el usuario, pues es el motor de búsqueda quien analiza e interpreta el texto para dar respuesta a la consulta.
Correspondencia de patrones: se utiliza el operador de truncamiento y lo corriente es utilizar una interfaz en la que el usuario, paso a paso, va introduciendo los diferentes parámetros.
Lola García Santiago en Extraer y visualizar informaciónen Internet: el Web Mining, cita a Pirolli y Card que diferencian 2 estilos diferentes de recuperación en la Web:
Sin embargo, y siguiendo la metáfora etológica, hoy podríamos añadir un tercer animal: el estilo hormiga, esto es, la recuperación cooperativa, la búsqueda de conexiones y asociaciones entre los documentos que es establecida por las comunidades web actuales y que se manifiesta mediante la proliferación de folksonomías, blogosferas, fotosferas, wikipedias, etc. métodos de indización y clasificación que una serie de comunidades web llevan a cabo de forma colaborativa, cooperativa y compartida. La presencia y desarrollo de redes sociales ha sido una constante desde el nacimiento de Internet, ya sea para intercambiar mensajes de correo electrónico por medio de las listas de distribución, el establecimiento de foros en línea, el uso de chats, compartir archivos mediante las redes P2P, la creación de comunidades de weblogs, el desarrollo de software libre en colaboración, etc. La socialización de redes de comunidades en línea ha sido imparable en casi todas las manifestaciones y servicios posibles nacidos al albur de Internet. Y, de esta forma, vemos que también ha afectado a la búsqueda y recuperación de la Web.
Frente a los ambientes altamente tecnologizados que han dado origen al uso de robots y agentes inteligentes para la indización automática o la utilización de los potentes motores de búsqueda que rastrean, indizan y clasifican la World Wide Web sin intervención humana alguna, surgen nuevas formas sociales de aproximación a la indización, la clasificación, la búsqueda y acceso al documento. Todas estas nuevas formas están basadas en el principio de colaboración y puesta en común del conocimiento. De esta forma, la interactividad de los nuevos medios no se limita a la comunicación del usuario con las máquinas, sino que refuerza la interactividad como proceso comunicativo entre las personas.
Un buscador curioso es Ms Dewey (http://msdewey.com). Aunque no destaca por su funcionalidad, sí es llamativo por el vistoso diseño de su interfaz ya que, además, de consistir en una caja con el típico formulario para poder realizar la consulta, ofrece una imagen que muestra a una señorita que realiza comentarios y gestos y que es capaz de responder a ciertos estímulos (por ejemplo, si se tarda en hacer la consulta o si no hay resultados). El fondo de la imagen no es la típica biblioteca, sino una ciudad futurista y la mujer, como se puede ver en la imagen, tampoco responde al tópico de la bibliotecaria al uso. Ello ha dado origen a una gran diversidad de opiniones en la red sobre la imagen estereotipada de la profesión bibliotecaria y de Ms Dewey, en particular. En realidad, no se trata de un chat-bot, sino de un buscador y muchos han comparado a Ms. Dewey con Google destacando esta nueva tendencia hacia lo visual, lo social, la diversión y la interacción.
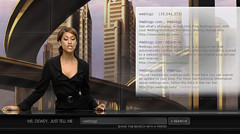


Fuentes: Buscador Ms. Dewey http://msdewey.com y Buscador Google http://www.google.es
![]() ACKERMANN, E.; HARTMAN, K.
ACKERMANN, E.; HARTMAN, K.
![]() AGUILAR
GONZÁLEZ, R. Monografía sobre motores de búsqueda. Yahoo Geocities, 2002.
http://www.geocities.com/motoresdebusqueda/inicio.html
AGUILAR
GONZÁLEZ, R. Monografía sobre motores de búsqueda. Yahoo Geocities, 2002.
http://www.geocities.com/motoresdebusqueda/inicio.html
![]() ARAUZO GALINDO, M. et al. Nuevas técnicas de búsqueda en
Internet. Madrid, Universidad Complutense, 2000.
http://www.fdi.ucm.es/asignaturas/ssii_sup/SI/grupo1/resumenes/Nuevas%20tecnicas%20de%20busqueda.htm
ARAUZO GALINDO, M. et al. Nuevas técnicas de búsqueda en
Internet. Madrid, Universidad Complutense, 2000.
http://www.fdi.ucm.es/asignaturas/ssii_sup/SI/grupo1/resumenes/Nuevas%20tecnicas%20de%20busqueda.htm
![]() BAEZA YATES,
Ricardo. Recuperación de la Información: Modelos, Estructuras de Datos,
Algoritmos y Búsqueda en la Web.
http://www.dcc.uchile.cl/~rbaeza/cursos/cc52d.pdf
BAEZA YATES,
Ricardo. Recuperación de la Información: Modelos, Estructuras de Datos,
Algoritmos y Búsqueda en la Web.
http://www.dcc.uchile.cl/~rbaeza/cursos/cc52d.pdf
![]() BELKIN, N., CROFT, W.B. (1987): “Retrieval
Techniques.” Annual Review of
Information Science and Technology, 22, 1987 [Volver]
BELKIN, N., CROFT, W.B. (1987): “Retrieval
Techniques.” Annual Review of
Information Science and Technology, 22, 1987 [Volver]
![]() BENITO AMAT, Carlos. Recuperación
en Internet: Cuatro modelos complementarios y una agenda para su integración
http://www.rediris.es/rediris/boletin/48/enfoque2.html
BENITO AMAT, Carlos. Recuperación
en Internet: Cuatro modelos complementarios y una agenda para su integración
http://www.rediris.es/rediris/boletin/48/enfoque2.html
![]() CALISHAIN, T. DORNFEST, R. Google:
los mejores trucos. Madrid, Anaya, 2004.
CALISHAIN, T. DORNFEST, R. Google:
los mejores trucos. Madrid, Anaya, 2004.
![]() CANALS CABIRÓ, I. "El concepto de hipertexto y el futuro de la
documentación". Revista Española de Documentación Científica, 13(2),
1990.
CANALS CABIRÓ, I. "El concepto de hipertexto y el futuro de la
documentación". Revista Española de Documentación Científica, 13(2),
1990.
![]() CHANG, G. et al. Mining the World Wide Web:
An information
search approach. Norwell, Massachusetts, Kluwer Academic Publishers, 2001.
[Volver]
CHANG, G. et al. Mining the World Wide Web:
An information
search approach. Norwell, Massachusetts, Kluwer Academic Publishers, 2001.
[Volver]
![]() CODINA, Lluís. "Posicionamiento web: conceptos y ciclo de vida". En Anuario
Hipertext.net mayo de 2004.
http://www.hipertext.net
CODINA, Lluís. "Posicionamiento web: conceptos y ciclo de vida". En Anuario
Hipertext.net mayo de 2004.
http://www.hipertext.net
![]() DELGADO DOMINGUEZ, A. Herramientas de búsqueda para la WWW.
Mallorca, Universitat Illes Balears, 1998.
http://dmi.uib.es/people/adelaida/CIVE/adecive.htm
DELGADO DOMINGUEZ, A. Herramientas de búsqueda para la WWW.
Mallorca, Universitat Illes Balears, 1998.
http://dmi.uib.es/people/adelaida/CIVE/adecive.htm
![]() DELGADO DOMÍNGUEZ, A. Mecanismos de recuperación de
información en la WWW. Mallorca, Universitat Illes Balears, 1998.
http://dmi.uib.es/people/adelaida/tice/modul6/memfin.pdf
DELGADO DOMÍNGUEZ, A. Mecanismos de recuperación de
información en la WWW. Mallorca, Universitat Illes Balears, 1998.
http://dmi.uib.es/people/adelaida/tice/modul6/memfin.pdf
Buscadores
URL:
http://www.hipertexto.info
Fecha de Actualización:
29/07/2018
Fundación Ricardo Lamarca, Ajedrez y
cultura (en constitución)
http://www.fundacionlamarca.es
Mapa de navegación
/ Tabla de contenido /
Mapa conceptual /
Tabla de documentos /
Buscador /
Bibliografía utilizada / Glosario de Términos /
Índice Temático /
Índice de Autores
![]() DOMINICH, S. "A unified mathematical definition of classical information
retrieval". Journal of the American Society for Information Science, 51 (7),
2000. [Volver]
DOMINICH, S. "A unified mathematical definition of classical information
retrieval". Journal of the American Society for Information Science, 51 (7),
2000. [Volver]![]() GARCÍA SANTIAGO, Lola. Extraer y visualizar información en Internet:
el Web Mining. Gijón, Trea, 2003 [Volver]
GARCÍA SANTIAGO, Lola. Extraer y visualizar información en Internet:
el Web Mining. Gijón, Trea, 2003 [Volver]![]() GÓMEZ DÍAZ, Raquel. "La evaluación en recuperación de la
información". Hipertext.net, núm. 1, 2003.
http://www.hipertext.net
GÓMEZ DÍAZ, Raquel. "La evaluación en recuperación de la
información". Hipertext.net, núm. 1, 2003.
http://www.hipertext.net![]() GONZÁLEZ, A. Resumen de Nuevas Técnicas de búsqueda en
Internet. Madrid, Facultad de Informática, Universidad Complutense, 2000.
http://www.fdi.ucm.es/asignaturas/ssii_sup/SI/ResumenNuevasTecnicas_jorge.htm
GONZÁLEZ, A. Resumen de Nuevas Técnicas de búsqueda en
Internet. Madrid, Facultad de Informática, Universidad Complutense, 2000.
http://www.fdi.ucm.es/asignaturas/ssii_sup/SI/ResumenNuevasTecnicas_jorge.htm![]() GONZÁLEZ, A. Searching for Google's Successor. San Francisco,
CA, Wired News, 1999.
http://www.wired.com/news/technology/0,1282,45905,00.html
GONZÁLEZ, A. Searching for Google's Successor. San Francisco,
CA, Wired News, 1999.
http://www.wired.com/news/technology/0,1282,45905,00.html![]() GONZALO, Carlos. "La selección de palabras clave para el
posicionamiento en buscadores: conceptos y herramientas de estudio". En
Anuario Hipertext.net mayo de 2004.
http://www.hipertext.net
GONZALO, Carlos. "La selección de palabras clave para el
posicionamiento en buscadores: conceptos y herramientas de estudio". En
Anuario Hipertext.net mayo de 2004.
http://www.hipertext.net![]() GRADO-CAFFARO,, M. Mecanismos/motores de búsqueda: ¿qué es lo
que buscan? Valencia, Quadernsdigital.net, 2000.
http://www.quadernsdigitals.net/articles/idg/mecanismos.htm
GRADO-CAFFARO,, M. Mecanismos/motores de búsqueda: ¿qué es lo
que buscan? Valencia, Quadernsdigital.net, 2000.
http://www.quadernsdigitals.net/articles/idg/mecanismos.htm![]() HAN, J. KAMBER, M.
Data mining: concepts and techniques. San Francisco, Morgan Kaufmann,
2000.
HAN, J. KAMBER, M.
Data mining: concepts and techniques. San Francisco, Morgan Kaufmann,
2000.![]() Inquirus. Welcome to Inquirus. Princeton, NEC Research Institute, 2002.
http://inquirus.nj.nec.com.
Inquirus. Welcome to Inquirus. Princeton, NEC Research Institute, 2002.
http://inquirus.nj.nec.com.
![]() LÓPEZ YEPES, José (coord.) Manual de
Ciencias de la Documentación. Madrid, Pirámide, 2002.
LÓPEZ YEPES, José (coord.) Manual de
Ciencias de la Documentación. Madrid, Pirámide, 2002.![]() MANCHÓN, E. Navegación jerárquica o categorial frente al uso del buscador.
Ainda.info, Barcelona, 2002.
http://www.ainda.info/navegacion_vs_buscador.html
MANCHÓN, E. Navegación jerárquica o categorial frente al uso del buscador.
Ainda.info, Barcelona, 2002.
http://www.ainda.info/navegacion_vs_buscador.html![]() MARCHIONINI, G. Information
seeking in electronic environments. Cambridge, University Pres, 1995.
MARCHIONINI, G. Information
seeking in electronic environments. Cambridge, University Pres, 1995.![]() MARCOS MORA, Mari Carmen. "Browsing y clustering: dos técnicas en auge para
la recuperación de información". En Rovira, C; Codina, L. (dir).
Documentación digital. Barcelona, Sección Científica de Ciencias de la
Documentación del Departamento de Ciencias Políticas y Sociales de la
Universidad Pompeu Fabra, 2004.
http://www.documentaciondigital.org
http://www.mcmarcos.com/pdf/2004_browsing-modd.pdf
[Volver]
MARCOS MORA, Mari Carmen. "Browsing y clustering: dos técnicas en auge para
la recuperación de información". En Rovira, C; Codina, L. (dir).
Documentación digital. Barcelona, Sección Científica de Ciencias de la
Documentación del Departamento de Ciencias Políticas y Sociales de la
Universidad Pompeu Fabra, 2004.
http://www.documentaciondigital.org
http://www.mcmarcos.com/pdf/2004_browsing-modd.pdf
[Volver]![]() MARCOS MORA, Mari Carmen. "La
visualización en el proceso de búsqueda y recuperación de información". En
Rovira, C.; Codina, L. (dir.). Documentación digital. Barcelona: Sección
Científica de Ciencias de la Documentación del Departamento de Ciencias
Políticas y Sociales de la Universidad Pompeu Fabra, 2004.
http://www.mcmarcos.com/pdf/2004_visualizacion-modd.pdf
MARCOS MORA, Mari Carmen. "La
visualización en el proceso de búsqueda y recuperación de información". En
Rovira, C.; Codina, L. (dir.). Documentación digital. Barcelona: Sección
Científica de Ciencias de la Documentación del Departamento de Ciencias
Políticas y Sociales de la Universidad Pompeu Fabra, 2004.
http://www.mcmarcos.com/pdf/2004_visualizacion-modd.pdf![]() MARTÍNEZ MÉNDEZ, Francisco Javier. Propuesta
y desarrollo de un modelo para la evaluación de la recuperación de información
en Internet. Tesis doctoral. Universidad de Murcia, 2002.
http://cervantesvirtual.com/FichaObra.html?Ref=10010&ext=pdf
MARTÍNEZ MÉNDEZ, Francisco Javier. Propuesta
y desarrollo de un modelo para la evaluación de la recuperación de información
en Internet. Tesis doctoral. Universidad de Murcia, 2002.
http://cervantesvirtual.com/FichaObra.html?Ref=10010&ext=pdf![]() MARTÍNEZ MÉNDEZ, Francisco.Javier.
El salto de la gestión de la información a la gestión del conocimiento.
Scire, vol. 5, nº 1, 1999.
http://www.um.es/gtiweb/fjmm/elsalto.doc
MARTÍNEZ MÉNDEZ, Francisco.Javier.
El salto de la gestión de la información a la gestión del conocimiento.
Scire, vol. 5, nº 1, 1999.
http://www.um.es/gtiweb/fjmm/elsalto.doc ![]() MOYA
ANEGÓN, Félix de. "Recuperación, difusión y edición de información
electrónica". En bibliotecas y centros de documentación: Internet para
bibliotecarios y documentalistas. Madrid, Servicio de Documentación
Multimedia UCM y Fundación Sánchez Albornoz, julio 2001.
http://multidoc.rediris.es/avila/
MOYA
ANEGÓN, Félix de. "Recuperación, difusión y edición de información
electrónica". En bibliotecas y centros de documentación: Internet para
bibliotecarios y documentalistas. Madrid, Servicio de Documentación
Multimedia UCM y Fundación Sánchez Albornoz, julio 2001.
http://multidoc.rediris.es/avila/![]() MOYA ANEGÓN, Félix de. "Sistemas
avanzados de recuperación de la información". En LÓPEZ YEPES, José.
Manual de Ciencias de la Documentación. Madrid, Pirámide, 2002.
MOYA ANEGÓN, Félix de. "Sistemas
avanzados de recuperación de la información". En LÓPEZ YEPES, José.
Manual de Ciencias de la Documentación. Madrid, Pirámide, 2002.![]()
![]()
![]()
![]() PICARD, J, and SAVOY, J.
Searching and Classyfing the web using hyperlinks: A logical approach. Neuchatel:
III, Universitè, 2001.
http://www.unice.ch/info/Gi/Papers/ictai.pdf
PICARD, J, and SAVOY, J.
Searching and Classyfing the web using hyperlinks: A logical approach. Neuchatel:
III, Universitè, 2001.
http://www.unice.ch/info/Gi/Papers/ictai.pdf![]() RIJSBERGEN, C.J.
Information Retrieval. Glasgow, University, 1999.
http://www.dcs.gla.ac.uk/~iain/keith
[Volver]
RIJSBERGEN, C.J.
Information Retrieval. Glasgow, University, 1999.
http://www.dcs.gla.ac.uk/~iain/keith
[Volver]![]() SALTON, G.
and Mc GILL, M.J. Introduction to Modern Information Retrieval. New York,
Mc Graw-Hill Computer Series, 1983.
SALTON, G.
and Mc GILL, M.J. Introduction to Modern Information Retrieval. New York,
Mc Graw-Hill Computer Series, 1983.![]() Search
Tools for Web Sites and Intranets. Home Page.
http://www.searchtools.com/index.html
Search
Tools for Web Sites and Intranets. Home Page.
http://www.searchtools.com/index.html![]() Search
Search Tools Products Listings in Alphabetical Order.
http://www.searchtools.com/tools/tools.html
Search
Search Tools Products Listings in Alphabetical Order.
http://www.searchtools.com/tools/tools.html![]() SEARCHING TECHNOLOGY. Searching. (Blog)
http://www.programacion.com/blogs/33_searching
SEARCHING TECHNOLOGY. Searching. (Blog)
http://www.programacion.com/blogs/33_searching![]() SHERMAN,
Chris. "The future revisited: what’s new with web search".
SHERMAN,
Chris. "The future revisited: what’s new with web search". ![]() TRAMULLAS, Jesús. Localización y acceso a la información:
http://www.tramullas.com/ri/index.html
TRAMULLAS, Jesús. Localización y acceso a la información:
http://www.tramullas.com/ri/index.html![]() TRAMULLAS, Jesús. "Sección 3:
La recuperación de información”. En Introducción a la Documática.
http://tek.docunautica.com/
TRAMULLAS, Jesús. "Sección 3:
La recuperación de información”. En Introducción a la Documática.
http://tek.docunautica.com/![]() TRAMULLAS, Jesús. "Sección 4. Sistemas informáticos de
tratamiento y recuperación de información documental". En Introducción
a la Documática.
http://tek.docunautica.com/
TRAMULLAS, Jesús. "Sección 4. Sistemas informáticos de
tratamiento y recuperación de información documental". En Introducción
a la Documática.
http://tek.docunautica.com/![]() TRAMULLAS, Jesús. OLVERA, M. Dolores. Recuperación en Internet. Madrid, Ra-Ma, 2001.
TRAMULLAS, Jesús. OLVERA, M. Dolores. Recuperación en Internet. Madrid, Ra-Ma, 2001.![]() TRAMULLAS SAZ, Jesús.
Bibliotecas y Centros de Documentación: Internet para bibliotecarios y
documentalistas.
http://multidoc.rediris.es/avila/paginas/tramullas.pdf
TRAMULLAS SAZ, Jesús.
Bibliotecas y Centros de Documentación: Internet para bibliotecarios y
documentalistas.
http://multidoc.rediris.es/avila/paginas/tramullas.pdf![]() TRAMULLAS SAZ, Jesús. "Recuperación de
información en el World Wide Web". En LÓPEZ YEPES, José.
Manual de Ciencias de la Documentación. Madrid, Pirámide, 2002.
TRAMULLAS SAZ, Jesús. "Recuperación de
información en el World Wide Web". En LÓPEZ YEPES, José.
Manual de Ciencias de la Documentación. Madrid, Pirámide, 2002.![]() TRYON, R. Cluster analysis. New York, MacGraw-Hill, 1939. [Volver]
TRYON, R. Cluster analysis. New York, MacGraw-Hill, 1939. [Volver]![]() TROTMAN,
Andrew. "Searching structured documents". Information Processing &
Management, Volume 40, Issue 4, July 2004
TROTMAN,
Andrew. "Searching structured documents". Information Processing &
Management, Volume 40, Issue 4, July 2004 ![]() VIANELLO OSTI, Mariana. El hipertexto entre la utopía y la aplicación:
identidad, problemática y tendencias de la web. Gijón, Trea, 2004.
VIANELLO OSTI, Mariana. El hipertexto entre la utopía y la aplicación:
identidad, problemática y tendencias de la web. Gijón, Trea, 2004.![]() VICEDO
GONZÁLEZ, José Luis. Recuperación de información de Alta Precisión: Los
sistemas de búsqueda de respuestas. http://www.sepln.org/monografiasSEPLN/monografiaVicedo.pdf
VICEDO
GONZÁLEZ, José Luis. Recuperación de información de Alta Precisión: Los
sistemas de búsqueda de respuestas. http://www.sepln.org/monografiasSEPLN/monografiaVicedo.pdf![]() VILLENA ROMÁN, J. Sistemas de
Recuperación de información. Valladolid, Departamento Ingeniería de Sistemas
Telemáticos, Universidad.
http://www.mat.upm.es/~jmg/doct00/Recupinfo.pdf
VILLENA ROMÁN, J. Sistemas de
Recuperación de información. Valladolid, Departamento Ingeniería de Sistemas
Telemáticos, Universidad.
http://www.mat.upm.es/~jmg/doct00/Recupinfo.pdf![]()
![]()
![]()
![]()
Robots y agentes
Bases de datos
SGBD y STRID
La web invisible
Portales o puertas de entrada a Internet
Recursos de referencia en línea
El problema de la lengua
Autora: María Jesús Lamarca Lapuente (currículo personal)
34.389 enlaces (10.436 externos y 23.953 internos)
![]()
![]()
Creative Commons
Reconocimiento-NoComercial-NoDerivados-Licencia España 2.5.
OTRAS PÁGINAS DE LA AUTORA
![]() Blog
El Cultural a la Puerta:
Blog
El Cultural a la Puerta:
http://puertadetoledo.blogspot.com/ 
Ageteca. Base de Datos de Gestión
Cultural:
http://www.agetec.org/ageteca


http://artesadigital.blogspot.com![]()
digital y
mundo analógico:
http://www.flickr.com/photos/artesadigital/
https://museodelajedrez.es

|
|
 Se parte de una determinada demanda de
información y se obtienen un conjunto de documentos o recursos (
Se parte de una determinada demanda de
información y se obtienen un conjunto de documentos o recursos (