
 


XSL o
Extensible Stylesheet Language no se trata de un único lenguaje, sino
de toda una familia de recomendaciones del World Wide Web Consortium
(http://www.w3.org/Style/XSL/) para expresar
Hojas de estilo en lenguaje XML. El lenguaje
XSL consta de tres partes:

Una hoja de
estilo XSLT especifica la presentación de una clase de documentos XML para
describir cómo un evento de clase se transforma dentro de un documento XML que
usa un vocabulario formateado tal como (X)HTML o XSL-FO.
A pesar de la existencia de las CCS u Hojas de Estilo en
Cascada que sirven para definir las presentaciones de los documentos en la
Web, se ha creado otra forma específica
para las presentaciones en XML. Esto se debe a que las CCS u Hojas de Estilo en
Cascada son eficaces para describir formatos y presentaciones, pero no
sirven para decidir qué tipo de datos deben ser mostrados y cuáles no deben
salir en la pantalla. CCS se utiliza con documentos XML en los casos en los que
debe mostrarse todo su contenido.
XLM no sólo sirve para especificar cómo queremos presentar
los datos de un documento XML, sino también para filtrar los datos de acuerdo
con ciertas condiciones. XSL es más complejo que las CCS
y permite muchas más
funciones que las Hojas de Estilo, ya que se asimila más a un lenguaje de
programación. Además de la presentación visual, XLS permite otras opciones
como la ejecución de bucles y sentencias, operaciones lógicas, ordenación de
datos, selecciones por comparación, utilización de plantillas, etc.
XSL o eXtensible Stylesheet Language
define o implementa el lenguaje de
estilo de los documentos escritos para XML. Desde 1997 varias
empresas informáticas como Arbortext, Microsoft e Inso se pusieron a trabajar en una
propuesta de XSL (antes llamado "xml-style") que presentaron al W3C
y cuyo fin era permitir modificar el aspecto de un documento. Con las
Hojas de
Estilo ya se podían lograr algunas mejoras en el aspecto del documento, pero XSL
permite otras muchas aplicaciones como múltiples
columnas, texto girado, orden de visualización de los datos de una tabla, múltiples
tipos de letra con amplia variedad en los tamaños, etc.
El lenguaje
SGML tiene su propio estándar para la transformación y representación de sus documentos
en forma de árbol, el DSSSL (Document Style Semantics and Specification Language, ISO10179), que en
realidad es un lenguaje de programación completo y muy potente basado en el
dialecto Scheme del lenguaje LISP. Por tanto, ya que XML es una versión reducida
de SGML parecía lógico hacer también una versión reducida del DSSSL, llamada en
este caso XSL (Extended Stylesheet Language).
El estándar XSL está basado
en el lenguaje de semántica y especificación de estilo de documento (DSSSL, Document
Style Semantics and Specification Language) y, por otro lado,
se considera más potente que las hojas de estilo en cascada (CSS, Cascading
Style Sheets), usado en un principio con el lenguaje
HTML. Las CSS se usan para visualizar simples estructuras de documentos XML
y hoy se ha conseguido una gran integración en XML con el protocolo
CSS2 (Cascading
Style Sheets, level 2) ofreciendo nuevas formas de composición y una más rápida
visualización), pero XSL es sumamente útil cuando se requiere una mayor potencia
de diseño en los documentos XML, sobre todo cuando éstos encierran datos
estructurados como tablas, organigramas, etc.
Así pues, básicamente, XSL es un lenguaje de hojas de estilos diseñado para su
utilización en la Web, que provee más funcionalidades que
las hojas de estilo en
cascada (CSS o Cascade Stylesheet) y proporciona un
representación de forma independiente de la plataforma utilizada o del medio de
representación de la información recogida en los documentos XML. Dicha representación
se crea mediante la formación de un árbol de objetos
de flujo (flow objects tree). Un objeto de flujo tiene una clase, la cual
representa una tarea o actividad de representación. Asimismo, un objeto de flujo
dispone de un conjunto de características, mediante las cuales se puede
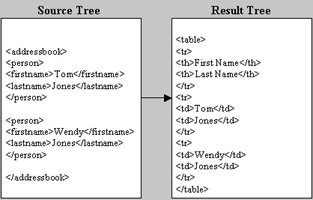
especificar mucho más la representación. La asociación de elementos en el árbol
origen con los objetos de flujo se lleva a cabo mediante las reglas de
construcción, las cuales contienen un patrón para identificar elementos
específicos en el árbol origen, y una acción para especificar un subárbol
resultante de objetos de flujo.
El procesador de hojas de estilo procesará de forma recursiva los elementos
del origen para producir un completo árbol de objetos de flujo. Además de las
reglas de construcción, XSL también soporta reglas de estilo, las cuales
permiten la mezcla de características. Mientras que una sola regla de
construcción puede ser invocada para un elemento en particular del origen,
pueden ser invocadas todas las reglas de estilo aplicables, permitiendo la mezcla de
características como en CSS.
Resumiendo, un hoja de estilo XSL describe el proceso de presentación a
través de un pequeño conjunto de elementos XML. Esta hoja, puede contener
elementos de reglas que representan a las reglas de construcción y elementos de
reglas de estilo que representan a las reglas de mezcla de estilos.
En cuanto a la inclusión de imágenes en las páginas XML, estas son sólo
enlaces, luego pueden representarse de cualquier modo soportado por las
especificaciones XLink y Xpointer, incluyendo la utilización de una sintaxis
similar a las imágenes HTML existentes. Estas especificaciones, sin embargo,
ofrecen un mejor control sobre la activación y cruce de
enlaces, por lo que
se puede elegir, por ejemplo, si se carga o no una imagen al cargar una página,
o mediante un clic del ratón, o en una
ventana adicional, sin tener que cambiar
el código.
Los soportes para formatos gráficos son
un problema específico de los
navegadores y visualizadores, y por tanto de la definición del XSL específico. XML por sí
mismo ni predice ni restringe nada. Los formatos que se perfilan como de mayor
utilidad son GIF, JPG, TIFF y CGM.
Para una explicación más detallada de cómo funciona XSL, se
puede consultar la web del World Wide Web Consortium:
What
Is XSL. (http://www.w3.org/Style/XSL/WhatIsXSL.html)
y para una información más completa sobre Hojas de estilo, ver la página Web style sheets
(http://www.w3.org/Style/)
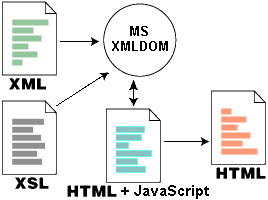
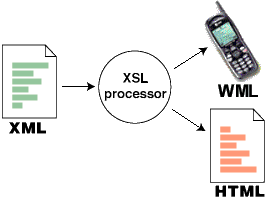
XSLT
XSLT está recogido en la Recomendación del W3C: XSL Transformations (XSLT) Version 2.0
http://www.w3.org/TR/xslt20/
Una transformación en el lenguaje XSLT está expresada en la
forma de una hoja de estilo, cuya sintaxis está bien formada en XML conforme a la Recomendación Namespaces in
XML (http://www.w3.org/TR/REC-xml-names/).
Una hoja de estilo generalmente incluye tanto elementos que
están bien definidos por XSLT como elementos que no están definidos por XSLT.
Los elementos definidos XSLT se distinguen por el uso de
namespaces o espacios de nombre
http://www.w3.org/1999/XSL/Transform,
tal y como se refiere en la
especificación como el XSLT namespace. Esta
especificación es una definición de la sintaxis y semántica de los espacios de
nombre XSLT.
El término hoja de estilo refleja el hecho de que uno de los
roles más importantes de XSLT es también añadir información de estilo a un
documento fuente XML para transformarlo en un documento que consta de objetos de
formato XSL, o en otro formato orientado a la presentación, tal como
HTML, XHTML, o
SVG.
Sin embargo, lo que caracteriza a XSLT es que se usa para un gran número de tareas de transformación, no
exclusivamente para aplicaciones de formato y presentación.
Una transformación expresada en XSLT describe reglas para
transformar cero o
 más recursos en árbol en cero o más recursos en árbol. La
estructura de estos árboles se describe en el Modelo de Datos (Data Model).
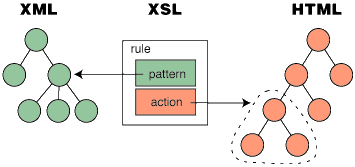
La transformación se realiza mediante un conjunto de reglas de patrón. Una regla
asocia un patrón, con nodos
iguales en el documento fuente, con un constructor de secuencias. En algunos casos,
la evaluación del constructor de secuencias originará
la construcción de nuevos nodos, los cuales pueden usarse para producir parte
del árbol resultante. La estructura de los árboles resultantes puede
ser completamente
diferente de la estructura de los árboles fuente. En la construcción del árbol
resultante,
los nodos de los árboles fuente pueden ser filtrados y reordenados, y puede
añadirse una nueva estructura. Este mecanismo permite que las hojas de
estilo sean aplicadas a una extensa clase de documentos que tienen estructuras de
recursos similares. más recursos en árbol en cero o más recursos en árbol. La
estructura de estos árboles se describe en el Modelo de Datos (Data Model).
La transformación se realiza mediante un conjunto de reglas de patrón. Una regla
asocia un patrón, con nodos
iguales en el documento fuente, con un constructor de secuencias. En algunos casos,
la evaluación del constructor de secuencias originará
la construcción de nuevos nodos, los cuales pueden usarse para producir parte
del árbol resultante. La estructura de los árboles resultantes puede
ser completamente
diferente de la estructura de los árboles fuente. En la construcción del árbol
resultante,
los nodos de los árboles fuente pueden ser filtrados y reordenados, y puede
añadirse una nueva estructura. Este mecanismo permite que las hojas de
estilo sean aplicadas a una extensa clase de documentos que tienen estructuras de
recursos similares.
Una hoja de estilo puede constar de
varios módulos de hojas de estilo contenidos en diferentes documentos XML. Para una transformación
dada, una de estas funciones es el módulo de hojas de estilo principal (principal stylesheet module.)
La hoja de estilo completa se adjunta para encontrar los módulos de hojas de
estilo directa o indirectamente referenciados desde el modulo de hoja de
estilo principal usando los elementos
xsl:include y
xsl:import .
Una aplicación concreta de XLT es, por ejemplo, su
utilización para diseñar un portal. Al poder separar
el contenido (XML) de la presentación (XLT) es posible utilizar un mismo
entramado o esqueleto para diseñar un portal en XML y cambiar la apariencia
gráfica utilizando una plantilla u hoja de estilo mediante XLT.
Xpath
XPath es un lenguaje para
direccionar partes de un documento XML, y está diseñado tanto para ser utilizado
con XSL como por XPointer. Se trata de una especificación W3C:
http://www.w3.org/TR/xpath
XPath también proporciona una serie de funcionalidades básicas para
manipular cadenas, números y booleanos. XPath opera sobre la
estructura lógica abstracta de un documento XML, más que en su sintaxis
superficial y se denomina así por el uso que hace de una notación de
caminos, como en los URLs, para navegar a través de la estructura jerárquica
de un documento XML.
Además de su uso para direccionar, XPath esta diseñado también de modo que
tiene un subconjunto natural que puede usarse para cotejar (comprobar si un nodo
encaja con un patrón o no); este uso de XPath se describe en XSLT.
XPath modela un documento XML como un árbol de nodos. Hay diferentes tipos de
nodos, incluyendo nodos elemento, nodos atributo y nodos texto. XPath
define un modo de calcular un valor de cadena para cada tipo de nodo. Algunos tipos de nodo también
tienen nombres. XPath es totalmente compatible con XMLNamespaces. Así, el nombre de un nodo se modela como un par
consistente en una parte local y un (quizá nulo) URI de
espacio de
nombres; a esto se le llama un nombre expandido.
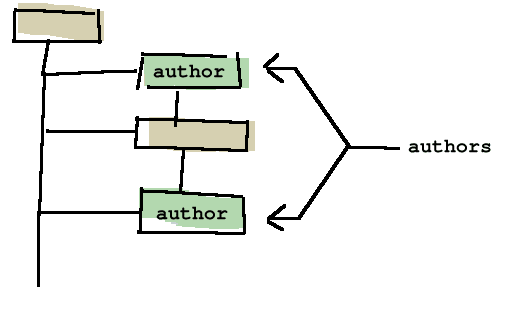
El
modelo de datos es el siguiente:
El
árbol contiene nodos. Hay siete tipos de nodos:
-
nodos raíz: El nodo raíz es la raíz del árbol. No aparecen nodos raíz salvo como
raíz del árbol. El nodo elemento del elemento de documento es hijo del nodo
raíz. El nodo raíz tiene también como hijos los nodos instrucción de
procesamiento y comentario correspondientes a las instrucciones de
procesamiento y comentarios que aparezcan en el prólogo y tras el fin del
elemento de documento. El valor de cadena del nodo
raíz es la concatenación de los valores de cadena
de todos los nodos texto descendientes del nodo
raíz en orden de documento. El nodo raíz no tiene nombre
expandido.
-
nodos
elemento: Hay un nodo elemento por cada elemento en el documento. Los
nodos elemento tienen un nombre expandido
calculado expandiendo el QName del elemento especificado en la etiqueta
de acuerdo con la Recomendación XML Names.
El URI de espacio de nombres del nombre expandido
del elemento será nulo si el QName no tiene
prefijo y no hay un espacio de nombres por defecto aplicable. Los hijos de un
nodo elemento son los nodos elemento, nodos comentario, nodos instrucción de
procesamiento y nodos texto que contiene. Las referencias de entidades tanto a
entidades internas como externas son expandidas. Las referencias de caracteres
son resueltas. El valor de cadena de un nodo
elemento es la concatenación de los valores de
cadena de todos los nodos texto descendientes
del nodo elemento en orden de documento. Los nodos elemento pueden tener un
identificador único (ID). Este es el valor del atributo que se declara en el
DTD como de tipo ID. No puede
haber dos elementos en un documento con el mismo ID. Si un procesador XML
informa de la existencia de dos elementos de un documento con el mismo ID (lo
cuales posible sólo si el documento es no valido) entonces el segundo
elemento en orden de documento debe ser tratado como si no tuviese ID. Si un
documento no tiene DTD, entonces ningún elemento del documento tendrá ID.
-
nodos texto: Los datos de carácter se agrupan en nodos texto. En cada nodo texto se
agrupan todos los datos de carácter que sea posible: un nodo texto nunca tiene
un hermano inmediatamente anterior o siguiente que sea nodo texto. El valor de cadena de los nodos texto son los
datos de carácter. Los nodos texto siempre tienen al menos un carácter. Cada
carácter en una sección CDATA se trata como datos de carácter. Así,
<![CDATA[<]]> en el documento
fuente será tratado igual que <.
Ambos darán lugar a un único carácter <
en un nodo texto en el árbol. Por tanto, una sección CDATA se trata como si
<![CDATA[ y
]]> se quitasen y cada aparición
de < y
& fuese reemplazada por
< y
& respectivamente. Cuando un
nodo texto que contiene un carácter <
se escribe como XML, el carácter <
debe ser escapado mediante, por ejemplo, el uso de
<, o incluyéndolo en una
sección CDATA.
-
nodos
atributo: Cada nodo elemento tiene asociado un conjunto de nodos
atributo; el elemento es el padre de cada uno de
esos nodos atributo; sin embargo, los nodos atributo no son hijos de su
elemento padre.
-
nodos espacio
de nombres: Cada elemento tiene un conjunto asociado de nodos espacio
de nombres, uno para cada uno de los distintos prefijos de espacio de nombres
con efecto sobre el elemento (incluyendo el prefijo
xml, que está implícitamente
declarado según la Recomendación de Espacios de Nombres XML) y uno para el espacio de nombres por
defecto si hay alguno con efecto sobre el elemento. El elemento es el padre de cada uno de los nodos espacio de nombres;
sin embargo, los nodos espacio de nombres no son hijos de su elemento padre.
Los elementos nunca comparten nodos espacio de nombres: Si dos nodos elemento
son distintos, entonces ninguno de los nodos espacio de nombres del primer
elemento será el mismo nodo que ningún nodo espacio de nombres del otro nodo
elemento. Esto significa que los elementos tendrán un nodo espacio de nombres:
-
para cada atributo del elemento cuyo nombre empiece por
xmlns:;
-
para cada atributo de un elemento ancestro cuyo nombre
empiece por
xmlns: salvo que el
propio elemento o un ancestro más cercano redeclaren el prefijo;
-
para atributos
xmlns,
si el elemento o alguno de sus ancestros tienen dicho atributo y el valor
del atributo en el más cercano de los elementos que lo tienen es no vacío.
-
nodos
instrucción de procesamiento: Hay un nodo instrucción de procesamiento
para cada instrucción de procesamiento, salvo para aquellas que aparezcan
dentro de la declaración de tipo de documento. Las instrucciones de
procesamiento tienen un nombre expandido: la
parte local es el destinatario de la instrucción de procesamiento; el URI de
espacio de nombres es nulo. El valor de cadena
de un nodo instrucción de procesamiento es la parte de la instrucción de
procesamiento que sigue al destinatario y todo el espacio en blanco. No
incluye la terminación ?>.
-
nodos
comentario: Hay un nodo comentario para cada comentario, salvo para
aquellos que aparezcan dentro de la declaración de tipo de documento. El valor de cadena de los comentarios es el
contenido del comentario sin incluir el inicio
<!-- ni la terminación
-->. Los nodos comentario no
tienen nombre expandido.
Para
cada tipo de nodo, hay una forma de determinar un valor de cadena
para los nodos de ese tipo. Para algunos tipos de nodo, el valor de cadena es
parte del nodo; para otros tipos de nodo, el valor de cadena se calcula a partir
del valor de cadena de nodos descendientes.
La construcción sintáctica básica en XPath es la expresión. Una expresión
se ajusta a la regla de producción Expr. Las expresiones son evaluadas para producir un objeto, que
tendrá uno de los siguientes cuatro tipos básicos:
- Conjunto de nodos (una colección desordenada de nodos sin
duplicados)
- booleano (verdadero o falso)
- número (un número en punto flotante)
- cadena (una secuencia de caracteres UCS)
La
evaluación de expresiones tiene lugar respecto a un contexto. XSLT y
XPointer especifican cómo se determina el contexto para las expresiones
XPath usadas en XSLT y XPointer respectivamente. El contexto consiste en:
-
Un nodo (el nodo contextual ).
-
un par de enteros positivos no nulos ( la posición contextual
y el tamaño contextual):
La
posición contextual es siempre menor o igual que el tamaño contextual.
-
un conjunto de asignaciones de variables (correspondencia
de nombres de variable a valores de variable. El valor de una variable
es un objeto, que puede ser de cualquiera de los tipos posibles para el valor
de una expresión, y puede también ser de tipos adicionales no especificados
aquí).
-
una biblioteca de funciones (correspondencia
de nombres de funciones a funciones. Cada función toma cero o más
argumentos y devuelve un único resultado).
-
el conjunto de declaraciones de espacios de nombres aplicables a la
expresión (correspondencia de prefijos
a URIs de espacios de nombres).
Un tipo importante de
expresión es el camino de localización. Un camino de localización selecciona un
conjunto de nodos relativo al nodo de contexto. El resultado de evaluar
una expresión que sea un camino de localización es el conjunto de nodos
seleccionados por el camino de localización. Los caminos de localización
pueden contener recursivamente expresiones utilizadas para filtrar conjuntos de
nodos. Un camino de localización se ajusta a la regla de producción LocationPath.
-
child::para
selecciona los elementos para hijos del nodo contextual
-
child::*
selecciona todos los elementos hijos del nodo contextual
-
child::text()
selecciona todos los nodos texto hijos del nodo contextual
-
child::node()
selecciona todos los hijos del nodo contextual, cualquiera que sea su tipo de
nodo
-
attribute::name
selecciona el atributo name del
nodo contextual
-
attribute::*
selecciona todos los atributos del nodo contextual
-
descendant::para
selecciona los elementos para
descendientes del nodo contextual
-
ancestor::div
selecciona todos los ancestros div del nodo contextual
-
ancestor-or-self::div selecciona los ancestros div del nodo contextual y, si el nodo contextual es un elemento div, el nodo contextual también
-
descendant-or-self::para
selecciona los elementos para descendientes del nodo
contextual y, si el nodo contextual es un elemento para , el nodo
contextual también
-
self::para
selecciona el nodo contextual si este es un elemento para
, en otro caso no selecciona nada
-
child::chapter/descendant::para
selecciona los elementos
para
descendientes de los elementos
chapter
hijos del nodo contextual
-
child::*/child::para selecciona todos los nietos para del nodo contextual
-
/ selecciona la
raíz del documento (que es siempre el padre del elemento de documento)
-
/descendant::para selecciona todos los elementos para en el mismo documento que el nodo contextual
-
/descendant::olist/child::item
selecciona todos los elementos
item
que tienen un padre
olist
y que estén en el mismo documento que el nodo contextual
-
child::para[position()=1]
selecciona el primer hijo para
del nodo contextual
-
child::para[position()=last()]
selecciona el último hijo para
del nodo contextual
-
child::para[position()=last()-1]
selecciona el penúltimo hijo para
del nodo contextual
-
child::para[position()>1]
selecciona todos los hijos para
del nodo contextual salvo el primero
-
following-sibling::chapter[position()=1]
selecciona el siguiente hermano chapter
del nodo contextual
-
preceding-sibling::chapter[position()=1]
selecciona el anterior hermano chapter
del nodo contextual
-
/descendant::figure[position()=42]
selecciona el cuadragésimo segundo elemento figure
en el documento
-
/child::doc/child::chapter[position()=5]/child::section[position()=2]
selecciona la segunda section
del quinto chapter del
elemento de documento doc
-
child::para[attribute::type="warning"]
selecciona todos los hijos para
del nodo contextual que tengan un atributo type
con valor warning
-
child::para[attribute::type='warning'][position()=5]
selecciona el quinto hijo para
del nodo contextual que tenga un atributo type
con valor warning
-
child::para[position()=5][attribute::type="warning"]
selecciona el quinto hijo para
del nodo contextual si ese hijo tiene un atributo type
con valor warning
-
child::chapter[child::title='Introduction']
selecciona los hijos chapter
del nodo contextual que tengan uno o más hijos title
con string-value
igual a
Introduction
-
child::chapter[child::title]
selecciona los hijos
chapter del nodo contextual que
tengan uno o más hijos title
-
child::*[self::chapter or self::appendix]
selecciona los hijos chapter
y appendix
del nodo contextual
-
child::*[self::chapter or self::appendix][position()=last()]
selecciona el último hijo chapter
o appendix del
nodo contextual
Hay
dos tipos de caminos de localización:
-
caminos
de localización relativos: consiste en
una secuencia de uno o más pasos de localización separados por
/. Los
pasos en un camino de localización relativo se componen de izquierda a derecha.
Cada paso selecciona un conjunto de nodos relativos a un nodo contextual. Una
secuencia inicial de pasos se une al paso siguiente de la siguiente forma.
La secuencia inicial de pasos selecciona un conjunto de nodos relativos a un
nodo de contexto. Cada nodo de ese conjunto se usa como nodo de contexto para el
siguiente paso. Los distintos conjuntos de nodos identificados por ese paso se
unen. El conjunto de nodos identificado por la composición de pasos es dicha
unión. Por ejemplo, child::div/child::para selecciona los elementos para
hijos de los elementos
div
hijos del nodo contextual, o, en otras palabras, los elementos
para
nietos que tengan padres
div.
-
caminos
de localización absolutos: consiste en /
seguido opcionalmente por un camino de localización relativo. Una
/ por si misma
selecciona el nodo raíz del documento que contiene al nodo contextual. Si es
seguida por un camino de localización relativo, entonces el camino de
localización selecciona el conjunto de nodos que seleccionaría el camino
de localización relativo relativo al nodo raíz del documento que contiene al
nodo contextual.
Un
paso de localización tiene tres partes:
-
un eje, que especifica la relación
jerárquica entre los nodos seleccionados por el paso de localización y el nodo
contextual,
-
una prueba de nodo, que especifica
el tipo de nodo y el nombre-expandido
de los nodos seleccionados por el paso de localización, y
-
cero o más predicados, que usan
expresiones arbitrarias para refinar aún más el conjunto de nodos seleccionado
por el paso de localización.
La
sintaxis del paso de localización es el nombre de eje y prueba de nodo
separados por dos caracteres de dos puntos, seguido de cero o más expresiones,
cada una entre paréntesis cuadrados. Por ejemplo, en child::para[position()=1]
,
child es el
nombre del eje,
para es la prueba de nodo y
[position()=1]
es un predicado.
El
conjunto de nodos seleccionado por el paso de localización es el que resulta de
generar un conjunto de nodos inicial a partir del eje y prueba de nodo, y a
continuación filtrar dicho conjunto por cada uno de los predicados
sucesivamente.
El conjunto de nodos inicial se compone de los nodos que tengan la relación con
el nodo contextual que se especifica en el eje, y tengan el tipo de nodo y nombre-expandido
especificados por la prueba de nodo. Por ejemplo, un paso de localización
descendant::para selecciona los
elementos para
descendientes del nodo contextual:
descendant
especifica que cada nodo en el conjunto de nodos inicial debe ser un
descendiente del contexto;
para
especifica que cada nodo en el conjunto de nodos inicial debe ser un elemento
llamado para
. El significado de algunas pruebas de nodos depende del eje.
El
conjunto de nodos inicial se filtra por el primer predicado para generar un
nuevo conjunto de nodos; este nuevo conjunto de nodos es entonces filtrado
usando el segundo predicado, y así sucesivamente. El conjunto de nodos final es
el conjunto de nodos seleccionado por el paso de localización. El eje afecta a
la forma en que se evalúa la expresión de cada predicado y, por tanto, la semántica
de un predicado se define con respecto a un eje.
Están
disponibles los siguientes ejes:
-
El eje
child
contiene los hijos del nodo contextual
-
El eje
descendant
contiene los descendientes del nodo contextual; un descendiente es un hijo o el
hijo de un hijo, etc; de este modo el eje descendant nunca contiene nodos
atributo o espacio de nombres
-
El eje
parent
contiene el padre del
nodo contextual, si lo hay
-
El eje
ancestor
contiene los ancestros del nodo contextual; los ancestros del nodo contextual
consisten en el padre
del nodo contextual y el padre del padre, etc; así, el eje ancestor siempre
incluirá al nodo raíz, salvo que el nodo contextual sea el nodo raíz
-
El eje
following-sibling
contiene todos los siguientes hermanos del nodo contextual; si el nodo
contextual es un nodo atributo o un nodo espacio de nombres, el eje following-sibling está vacío
-
El eje
preceding-sibling
contiene todos los hermanos precedentes del nodo contextual; si el nodo
contextual es un nodo atributo o un nodo espacio de nombres, el eje preceding-sibling
está vacío
-
El eje
following contiene todos los nodos
del mismo documento que el nodo contextual que están después de este según el
orden del documento, excluyendo los descendientes y excluyendo nodos atributo y
nodos espacio de nombres
-
El eje
preceding
contiene todos los nodos del mismo documento que el nodo contextual que están
antes de este según el orden del documento, excluyendo los ancestros y
excluyendo nodos atributo y nodos espacio de nombres
-
El eje
attribute
contiene los atributos del nodo contextual; el eje estará vacío a no ser que
el nodo contextual sea un elemento
-
El eje
namespace
contiene los nodos espacio de nombres del nodo contextual; el eje estará vacío
a no ser que el nodo contextual sea un elemento
-
El eje
self
contiene simplemente el propio nodo contextual
-
El eje
descendant-or-self
contiene el nodo contextual y sus descendientes
-
El eje
ancestor-or-self
contiene el nodo contextual y sus ancestros; así, el eje "ancestor-or-self"
siempre incluirá el nodo raíz
Los ejes
ancestor,
descendant,following,
preceding y
self
particionan un documento (ignorando los nodos atributo y espacio de nombres): no
se superponen y juntos contienen todos los nodos del documento.
Cada
eje tiene un tipo principal de nodo. Si un eje puede contener elementos,
entonces el tipo principal de nodo es elemento; en otro caso, será el tipo de
los nodos que el eje contiene. Así,
- Para el eje attribute, el tipo de nodo principal es
atributo.
- Para el eje namespace, el tipo de nodo principal es
espacio de
nombres.
- Para los demás ejes, el tipo de nodo principal es
elemento.
Una
prueba de nodo que sea un QName (nombre calificado) es verdadera si
y solo si el tipo del nodo es el tipo principal de nodo y tiene un nombre
expandido igual al nombre
expandido especificado por el QName. Por ejemplo,
child::para
selecciona los elementos para
hijos del nodo contextual; si el nodo contextual no tiene ningún hijo
para ,
seleccionará un conjunto vacío de nodos.
attribute::href selecciona el atributo
href del
nodo contextual; si el nodo contextual no tiene atributo
href,
seleccionará un conjunto vacío de nodos.
Un
QName en la prueba de
nodo se expande en un nombre
expandido utilizando las declaraciones de espacio de nombres del contexto de
la expresión. Esta es la misma forma en que se hace la expansión para los
nombres de tipos de elemento en las etiquetas de inicio y fin salvo que el
espacio de nombres por defecto declarado con
xmlns
no se utiliza: si el QName
no tiene prefijo, entonces el URI de espacio de nombres es nulo (esta es la
misma forma en que se expanden los nombres de atributos). Será un error que el
QName tenga un prefijo
para el cual no haya una declaración de espacio de nombres en el contexto de la
expresión.
Una
prueba de nodo * es verdadera para
cualquier nodo del tipo principal de nodo. Por ejemplo,
child::*
seleccionará todo elemento hijo del nodo contextual, y
attribute::* seleccionará
todos los atributos del nodo contextual.
Una
prueba de nodo puede tener la forma NCName:*.
En este caso, el prefijo es expandido de la misma forma que con un QName, utilizando las declaraciones de espacio de nombres del contexto. Será un
error que no haya una declaración de espacio de nombres para el prefijo en el
contexto de la expresión. La prueba de nodo será verdadera para cualquier nodo
del tipo principal cuyo nombre expandido
tenga el URI de espacio de nombres al qué el prefijo se expande, con
independencia de la parte local del nombre.
La
prueba de nodo
text() es verdadera para
cualquier nodo de texto. Por ejemplo,
child::text() seleccionará los nodos de texto hijos del nodo contextual. Análogamente,
la prueba de nodo
comment()
es verdadera para cualquier nodo comentario, y la prueba de nodo
processing-instruction()
es verdadera para cualquier instrucción de procesamiento. La prueba
processing-instruction()
puede tener un argumento que sea Literal;
en este caso, será verdadera para cualquier instrucción de procesamiento que
tenga un nombre igual al valor del Literal.
Una
prueba de nodo node()
es verdadera para
cualquier nodo de cualquier tipo que sea.
Los
ejes están orientados hacia adelante o hacia atrás. Un eje que solo puede
contener el nodo contextual o nodos que están a continuación del nodo
contextual según el orden
de documento es un eje hacia adelante. Un eje que solo puede contener el
nodo contextual o nodos que están antes del nodo contextual según el orden
de documento es un eje hacia atrás. Así, los ejes ancestor,
ancestor-or-self, preceding, y
preceding-sibling son ejes hacia atrás; todos
los demás ejes son hacia adelante. Dado que el eje self siempre tendrá a lo
sumo un nodo, no supone ninguna diferencia que sea un eje hacia adelante o hacia
atrás. La posición de proximidad de un miembro de un conjunto de nodos
con respecto a un eje se define como la posición del nodo en el conjunto
ordenado según el orden de documento si el eje es hacia adelante y según el
orden inverso de documento si el eje es hacia atrás. La primera posición es 1.
Un
predicado filtra un conjunto de nodos con respecto a un eje para producir un
nuevo conjunto de nodos. Por cada nodo en el conjunto de nodos a filtrar, la
PredicateExpr
es evaluada con dicho nodo como nodo contextual, con el número de nodos en el
conjunto de nodos como tamaño contextual, y con la posición
de proximidad del nodo en el conjunto de nodos respecto al eje como posición
contextual; si PredicateExpr
se evalúa como verdadera para ese nodo, el nodo se incluye en el nuevo conjunto
de nodos; en otro caso, no se incluye.
Una
PredicateExpr
se evalúa evaluando la Expr y convirtiendo el resultado en un booleano. Si el resultado es un número, se
convertirá en verdadero si el número es igual a la posición contextual y se
convertirá en falso en otro caso; si el resultado no es un número, entonces el
resultado se convertirá igual que con una llamada a la función
boolean.
Así un camino de localización
para[3] es
equivalente a
para[position()=3] .
Las expresiones se analizan dividiendo primero la cadena de caracteres a
analizar en tokens y a continuación analizando la secuencia de tokens
resultante. Se puede usar libremente espacio en blanco entre tokens.
El proceso de tokenización se describe en Estructura Léxica. En la
tokenización, siempre se devuelve el token más largo posible.
La especificación también alude a
las funciones que las implementaciones de XPath deben incluir
siempre en la librería de funciones que se usa para evaluar expresiones. Hay
funciones de conjunto de nodos, de cadenas, booleanas y numéricas.
Existe también una Especificación llamada
XML Path Language (XPath) 2.0.
(http://www.w3.org/TR/xpath20/).
En la versión 2, XPath es un lenguaje de
expresión que permite el procesamiento de conformidad al modelo de
datos definido en XQuery 1.0 and XPath 2.0 Data Model.
(http://www.w3.org/TR/xpath-datamodel/) El modelo de
datos también ofrece una representación de árbol de los documentos XML. XPath
2.0 es un conjunto de XPath 1.0 con algunas capacidades añadidas, como la de soportar un
conjunto más rico de tipos de datos, y usar los
esquemas de XML Schema para validar los documentos.
XSL Formatting
Objects (XSL-FO)
El eXtensible Stylesheet Language Formatting Objects (XSL-FO) es una
Recomendación del W3C: http://www.w3.org/TR/xsl.
Desafortunadamente, el término XSL se usa a menudo tanto en un sentido genérico,
como en otro específico, lo que crea una gran confusión. Como ya hemos afirmado,
genéricamente, XSL es, en la actualidad, una familia de 3 Recomendaciones
producidas por el W3C: XSL Transformations (XSLT), XML Path Language (XPath), y eXtensible Stylesheet Language (el uso específico de XSL). Para borrar la
confusión entre los usos genéricos y específicos de XSL, mucha gente se refiere
a la última especificación (que actualmente especifica el formateador de objetos)
como XSL-FO.
Hay también una confusión importante sobre las
diferencias entre XSL-FO y CSS. CSS o Cascading Style Sheets
es un
lenguaje de hojas de estilo externo. Se usa para aplicar estilo a un documento XML o
HTML para seleccionar elementos en el documento y adjuntar propiedades de
estilo a cada elemento seleccionado. En contraste, XSL-FO es un lenguaje
para describir un estilo de documento completo, incluyendo la organización
de su contenido, estilo, disposición y reglas de selección de
la composición, entre ellas la necesidad de formatearlo y paginarlo. Para usarlo,
se aplica
una hoja de estilo XSLT (stylesheet XSLT) o algún otro mecanismo al documento
original XML o XHTML, transformándolo en un documento XSL-FO, lo que se llama
alimentar un formateador.
El desarrollo de XSL-FO se debió a 3
razones fundamentales. La primera es que no existía un lenguaje
para describir la paginación de documentos complejos en la Web. Todavía hoy,
cuando se imprime un documento desde un navegador, la línea de texto que
aparece al final de la página, aparece a menudo cortada. Si esto sucede en un
dibujo, medio dibujo aparece en la primera página y un espacio en una caja negra
aparece en la siguiente página. CSS-2.0 añadió algún soporte básico para
la paginación, pero todavía no ha sido plenamente implementado en los
navegadores comunes. Es más, CSS trabaja solamente con documentos cuyo
contenido está organizado de la misma forma que la presentación —no elementos
que saltan, ni
elementos presentados fuera de secuencia, etc.
La segunda razón es que no existía forma
para operar con documentos largos y con composiciones complejas. La
Web estándar no soporta cosas como tablas de contenidos,
llamadas, notas al pie, notas al final, índices o múltiples artículos en una
página, composiciones comunes en periódicos, revistas o páginas de catálogos.
Y la tercera es que el nivel de la tipografía en
CSS
no bastaba para imprimir documentos, puesto que CSS se limitaba únicamente a las
necesidades de los navegadores, y
no era un formato adecuado para la impresión.
Objetivos del Working Group
Así pues, el grupo de trabajo del XSL-WG, estableció un número de objetivos para el
diseño de XSLT y XSL-FO:
-
XSLT y XSL-FO se expresarían en
sintaxis pura XML . Esto produciría dos significativas ventajas: XSLT y XSL-FO
trabajarían con la existencia de parsers XML, y podrían ser validados y
manipulados usando herramientas XML existentes.
-
XSLT y XSL-FO deberían
declarar un conjunto de elementos y atributos plenamente descriptivos para
obtener los resultados deseados. (En contraste, un lenguaje de procedimiento o
procesado tal como
PostScript que describe los algoritmos que producirán el resultado.) Aunque las
expresiones de programación están permitidas en algunos atributos, no se
requeriría usarlas y no se requería scripting interna.
-
XSL se crearía sobre CCS y extendería y
aumentaría CSS-2 para cubrir los espacios donde éste no resuelve los problemas. Al mismo tiempo,
podría compartir muchas propiedades de estilo y muchos de los modelos de formato
y disposición de las CSS. Así pues, XSL incluiría soporte para paginar documentos de gran complejidad, para dotar de estilo
a documentos en los que sea muy importante la composición del contenido
(tales como libros de texto, manuales, contratos o catálogos
industriales), XSL añadiría soporte para características como notas al pie, notas finales, globos, índices, tablas de contenidos, diferentes y
homogéneos modelos y plantillas de páginas, etc.
También
añadiría soporte para documentos de composición reglada como periódicos,
revistas, catálogos y folletos. Y, por supuesto, continuaría soportando los
documentos navegables que podrían ser soportados
usando CSS.
-
XSL debería cubrir los
requerimientos de presentación básica para la mayor parte de usos de impresión y
para un gran rango de dispositivos de presentación y visualización, incluyendo reflujo o repaginación
para dispositivos de bolsillo ; y para los requerimientos de
accesibilidad.
Para hacer todo esto, era necesario proveer un mecanismo
de transformación que reorganice, filtre el contenido para una mejor
presentación para el medio deseado y los requerimientos de acceso. Esto hace
necesario separar el diseño de la composición y los controles de paginación
secuencia, así como que el mismo estilo de contenido puede ser situado en
disposiciones diferentes. El mecanismo de transformación podría proveer una manera
para modificar la presentación (estilo y composición) para soportar
requerimiento de accesibilidad tales como un texto largo o fuentes alternativas,
negro sobre blanco o blanco sobre negro (o alternar esquemas de colores),
alternar la navegación y la presentación aural, etc.
-
XSL-FO
mejoraría la tipografía y las características de disposición de los formatos de
páginas existentes y sería compatible con los principales modelos de formato.
Además, SXL- FO tendría soporte multilingüe incluyendo el uso de Unicode y reglas bidireccionales de Unicode. Soportaría un número de
características especiales de composición usadas en Asia y los lenguajes del
Medio Este, o que esto fuera fácil de hacer en el futuro. XSL-FO proveería
soporte para características multilingües de fuentes de moderna tecnología,
tales como fuentes libres.
-
En adición a los
objetivos del proyecto, el Working Group también estableció la necesidad
de publicar alguna guía sobre cómo usar XSL-FO. Lo más importante es que XSL-FO estuviera
explícitamente no diseñado para la autoría manual, esto es, que fueran generadas
por máquina a través de XSLT, la programación y la composición o las aplicaciones de
diseño. Este no era un nuevo concepto, ya que en la publicación dinámica actual de
websites se almacena rutinariamente su contenido en XML neutral y entonces
las máquinas generan el HTML apropiado para el
navegador.
Mucha gente se hace las siguientes
preguntas: "Si ya existen las CSS ¿para qué se necesita XSL-FO?” o "Si existen unas maravillosas herramientas de composición WYSIWYG, muchas de las cuales pueden procesar XML,
¿por qué usar XSL-FO?" Además, muchas personas piensan también que las hojas de estilo CSS y XSL
son bastante más difíciles y complicadas de escribir que utilizar las agradables
interfaces gráficas GUIs de programas de composición tales como
FrameMaker o
InDesign.
Sin embargo, los requerimientos de la industria de la
edición y la publicación son
amplios y diversos. Algunos
documentos requieren elementos de creación profesional para interactivamente modificar la
disposición, el contenido y la tipografía para así obtener un resultado aceptable;
otros documentos resultan mejores cuando son generados y formateados bajo demanda usando
sistemas basados en reglas. XSL-FO está diseñado para cubrir este agujero en el
formato bajo demanda en el sector de la industria; en donde es ideal para
productos de colecciones de páginas tales como Adobe Document Server.
Los requerimientos del sector de formato bajo demanda son
totalmente diferentes de aquellos diseñados para la
interacción, y herramientas de
composición WYSIWYG tales como FrameMaker e
InDesign. Hoy las herramientas de
composición
WYSIWYG
son muy buenas en la creación y perfeccionamiento de
documentos individuales, que es el motor primordial de la existencia de muchas de las
publicaciones tradicionales de la industria. En estos productos
WYSIWYG,
el contenido, el estilo y la composición están estrechamente ligadas al
documento y así, mover el documento a un medio alternativo (pantalla versus papel,
pantallas con diferentes tamaños o formatos) es una tarea ardua,
complicada y difícil. Otra área donde las herramientas
WYSIWYG
no son buenas es
en la producción de cientos de documentos cuyo contenido está sacado de una
base de datos y vertido en documentos a modo de plantillas donde cambian los
datos. En estos casos, se necesita que pueda darse a toda la colección de
documentos un aspecto común y agradable, y que sea fácil de elaborar.
Existen dos situaciones en las que es mejor operar con
software de composición
interactiva: cuando un diseñador necesita control creativo de la disposición, y
cuando un escritor o ilustrador necesita trabajar con el contenido mientras
simultáneamente ve o modifica esta composición. En la edición de revistas, por
ejemplo, el diseño de páginas es en muchos casos complejo y la composición de cada página
está hecha a la medida del contenido. (A menudo, ambos, el contenido y la
composición, serán ajustados de forma repetida para obtener el resultado
deseado.) En la producción de folletos, los gráficos y la composición deben ser
producidos al mismo tiempo y los cambios influyen los unos en los otros. También
en la
producción de periódicos, el contenido está a menudo editado para rellenar un
espacio exacto. En estas situaciones, las herramientas de composición
interactiva como Adobe InDesign y Adobe InCopy son la elección apropiada.
Sin embargo hay
situaciones donde la composición interactiva es imposible. Como ejemplo podemos
poner casos en los que la generación del contenido de los documentos viene dada en respuesta a
requerimientos individuales (quizás a través del servidor Web) o variaciones de
un documento plantilla donde varían algunos campos de datos. En tales
situaciones, XSL-FO corriendo en un producto como Adobe Document Server es la
elección apropiada.
Otro objetivo importante es imprimir
únicamente el contenido que toma gráficos y
texto desde las mismas fuentes o recursos de contenido
neutro XML que están siendo dinámicamente publicados en la Web. XSL-FO,
en conjunción con la especificación XML compañera, XML SVG,
ofrece una manera clara
para unificar las herramientas de publicación dinámica orientadas a la Web y
la impresión.
Así pues, XSL-FO es un formato intermediario entre el medio
XML neutro y el medio dependiente de la salida. Si se alimenta con contenido
estructurado XML y una hoja de estilo XSLT a un procesador XSLT, el resultado es
XSL-FO. Luego se alimenta XSL-FO, junto con fuentes métricas y algún gráfico o
imagen externa, dentro de un formateador XSL-FO, y el resultado es un documento
paginado (en PDF o código para imprimir) que puede ser visualizado o impreso.
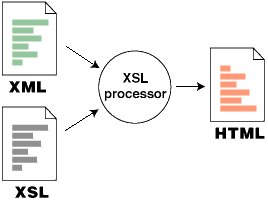
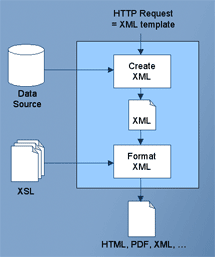
La siguiente imagen muestra a la perfección el funcionamiento
de todo este proceso:

Fuente: DEACH, Stephen. "What Is XSL-Fo and When Should I Use It?"
The
Seybold Report . Vol. 2, No. 17. December 9, 2002.
http://www.seyboldreports.com/TSR/free/0217/techwatch.html
En resumen,
el lenguaje XSL o
Extensible Stylesheet Language
abarca una serie de tecnologías que se pueden compendiar de
la siguiente forma:
XSLT (XSL Transforms): La palabra
“Transforms” muestra exactamente en qué consiste esta parte del estándar pues
describe cómo los documentos XML pueden ser filtrados y convertidos en otros
documentos XML, incluyendo archivos XSL-FO. Desafortunadamente, un XSLT que
especifica este tipo de conversión se denomina hoja de estilo, lo cual crea
una gran confusión debido al uso tradicional del término. Una hoja de estilo XSLT
es un concepto que encierra una rutina de búsqueda y sustitución más
sofisticada que el de las hojas de estilo anteriores.
Xpath (XSL Path Language): Se usa con XSLT para
especificar las partes de un documento XML a las cuales se aplica la
transformación. Los modelos XPath en documentos XML son un árbol de nodos con
padre-hijos y relaciones entre ellos próximas-lejanas. Estos nodos son de
diferentes tipos: nodos elemento, nodos atributo, nodos texto, etc. Si XSLT es
una herramienta de búsqueda y reemplazo sofisticada, entonces Xpath es la manera
para seleccionar qué nodos o tipos de nodos buscar.
XSL-FO (XSL Formatting Objects):
El archivo XSL-FO contiene el medio y apariencia específica de los objetos
formateados para fabricar la página (o, para
salida de audio, el discurso). Para el medio impreso, los objetos formateados (formatting
object) pueden incluir
caracteres, bloques de texto, imágenes, tablas, bordes, páginas maestras y otros
elemento similares.
XSL-FO no es un lenguaje de descripción
de página. Puede especificar varias reglas de composición (por ejemplo, dónde
situar una ruptura de página) y requerimientos (por ejemplo, ir a una nota al
pie en el final de la página), pero no determina la colocación actual de cada
elemento. Esto está determinado por el motor paginador
XSL-FO, llamado formateador (formatter).
La salida de un formateador no necesita
necesariamente tener asignada una impresora, esto quiere decir que la salida
puede ser un archivo PostScript
o PDF, que necesitaría un software adicional de interpretación. Hay varios
formateadores XSL-FO que se usan comúnmente para generar PDF.
Bibliografía
 BOSAK, John (comp.). DSSSL Online Application Profile.
http://www.ibiblio.org/pub/sun-info/standards/dsssl/dssslo/dssslo.htm
BOSAK, John (comp.). DSSSL Online Application Profile.
http://www.ibiblio.org/pub/sun-info/standards/dsssl/dssslo/dssslo.htm
DEACH, Stephen. "What Is XSL-Fo and When Should I Use It?" The Seybold Report
. Vol. 2, No. 17. December 9, 2002.
http://www.seyboldreports.com/TSR/free/0217/techwatch.html
PAWSON, Dave. XSL Frequently Asked Questions.
http://www.dpawson.co.uk/xsl/xslfaq.html
W3C.Extensible Markup Language XML.
http://www.w3.org/TR/REC-xml/
W3C. The
Extensible Stylesheet Language Family (XSL).
http://www.w3.org/Style/XSL/
W3C. Extensible Stylesheet Language (XSL).
http://www.w3.org/TR/xsl/
W3C.
How to add style to XML?
http://www.w3.org/Style/styling-XML
W3C. Namespaces in
XML.
http://www.w3.org/TR/REC-xml-names/
(traducción al castellano: POZO, Juan R.
Espacios de Nombres en XML.
http://html.conclase.net/w3c/xml-names-es/
W3C. Web Style Sheets. Home Page.
http://www.w3.org/Style/
W3C. What is XSL?
http://www.w3.org/Style/XSL/WhatIsXSL.html
W3C.
XML in 10 points.
http://www.w3.org/XML/1999/XML-in-10-points.html (traducción al castellano.
GUTIÉRREZ RESTREPO, Emmanuelle. XML en 10 puntos.
http://www.sidar.org/recur/desdi/traduc/es/xml/xml10p/xml10p.htm)
W3C. XML Path Language (XPath).
http://www.w3.org/TR/xpath
(traducción al castellano. GÓMEZ DUASO, Juan.
XML Path Language (XPath). (http://www.w3.org/TR/xpath)
por Sid@r.org: http://www.sidar.org/traduc/xpath.html)
W3C.
XML Path Language (XPath) 2.0.
http://www.w3.org/TR/xpath20/
W3C.
XSL Transformations (XSLT).
http://www.w3.org/TR/xslt
|




